Meet Haiper Ai
Haiper is a London-based AI text-to-video generator startup founded by former Google DeepMind researchers Yishu Miao and Ziyu Wang.

The company has just introduced Haiper 1.5, an advanced AI video generation model that challenges established names like RunwayML and Sora (which, to be fair, isn't out for the general public yet). Haiper 1.5 can generate 8-second-long clips, doubling the previous model’s capacity, with extensions up to 4 seconds. It includes an integrated upscaler that improves video quality to 1080p with a single click and a new image generation model for streamlined content creation.
Today, I've tried the platform for the first time and my first impressions are actually pretty good.

Prompt was taken from my examples for dynamic movement prompts in one of my previous posts:
Medium shot of the car, tracking shot following its movement on the reflective surface, highlighting the reflections and neon lights.
This is a damn fine result, don't you think?
Haiper Key Features
- Realistic physical motion replication
- High-quality output for impressive and engaging projects
- User-friendly interface suitable for all skill levels
- Intuitive design for efficient content creation
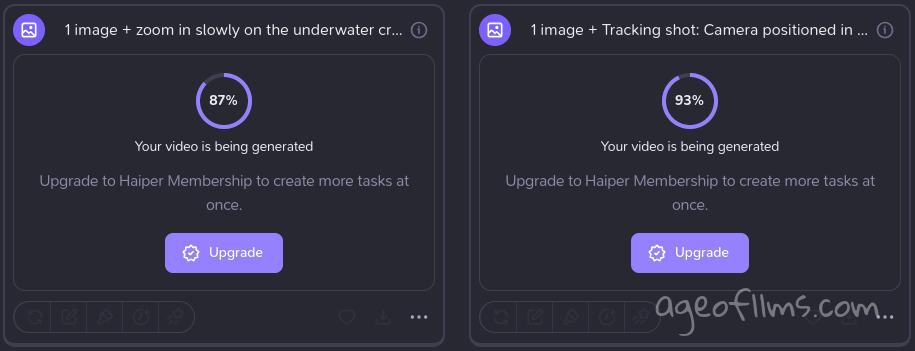
I especially liked the progress indicators, giving you approximate idea of how long your generations might take.
And the most exciting part is image keyframes are in the pipeline! I find that keyframe feature has been revolutionary and this was what glued me to Luma's solution primarily.
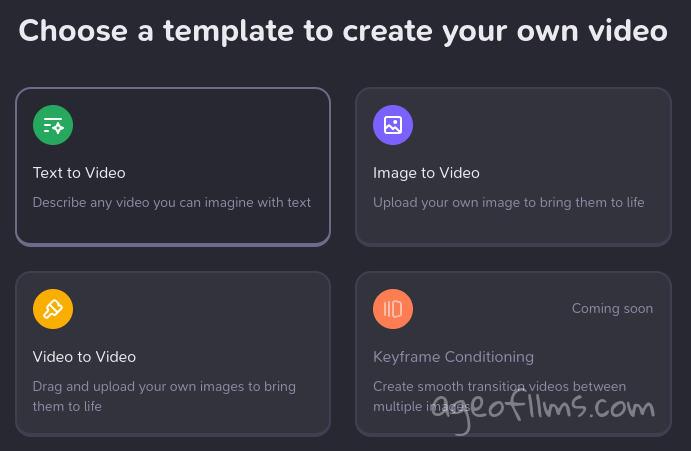
If Haiper can pull off keyframes, I reckon they'll have a real competitive advantage against both RunwayML and Luma Labs. The video quality is on par with Runway's latest Gen-3 Alfa and they already have 1 image as prompt option, they only need to add a second keyframe to beat what Luma's Dream Machine is offering, since the motion aspect does seem to be superior at times. I've tried the same source images and prompts in both Luma and Haiper and found that Haper rendered the motion more realistically on some occasions. It also managed to animate my steampunk dragon image which has a hella intricate design, although Luma did a better job on it still. So it's a neck and neck, both startups are developing, everyone benefits form more competition in the area.
Pricing and Plans
The service offers three plans: Free, Explorer, and Pro, all currently in beta, so they may be adjusted in the future. The Free plan costs nothing and provides basic features with limitations, including 10 daily creations and 300 credits. The Explorer plan, priced at $10 per month, offers unlimited creations, more credits (1500), and early access to some new features. The Pro plan, at $30 per month, provides the most comprehensive package with unlimited creations, the highest number of credits (5000), and additional perks like watermark-free videos, commercial use rights, and private creation capabilities. Both paid plans allow for more concurrent creations than the free tier. All plans are billed monthly, with a yearly option offering a 20% discount.
| Feature | Free (beta) | Explorer (beta) | Pro (beta) |
|---|---|---|---|
| Price | $0 (Free forever) | $10 /month | $30 /month |
| Billing | - | Billed monthly | Billed monthly |
| Creations per day | 10 | Unlimited (beta) | Unlimited (beta) |
| Credits | 300 | 1500 non-expiring per month | 5000 non-expiring per month |
| Concurrent creations | 3 | 5 | 10 |
| Watermark-free videos | |||
| Commercial use | |||
| Private creation | |||
| Early access to new features | - | Limited free | More features coming soon |
Credits-wise, creating an 8-second video or extending any video by 4 seconds costs 40 credits. But shorter generations - 2 or 4 seconds come free.
On free plan, even if your credits haven't run out yet, but you've generated 10 videos, you're done for the day. That's kind of common practice:
My First Tests of Hairper
Five creations on my first day. 1. Girl on a bike - Mifjourney image, 2. Steampunk Dragon - Dall-e image, 3. Woman in Ethnic Dress - text-to-video, 4 Cat - Dall-e image, 5 Underwater Creature - Midjourney image.
Haiper plans to improve its perceptual foundation models to better understand the world.
They ambitiously aim to create AGI that can replicate the emotional and physical aspects of reality, covering tiny details like light, motion, texture, and interactions between objects, to create realistic content.
Last modified 24 July 2024 at 19:27
Published: Jul 20, 2024 at 4:44 AM