Short Luma Dream Machine Video from 3 Images as Keyframes
As I keep exploring visual generative AI, I've decided to showcase another video, this time just a 10 seconds long one, which was made using 3 images as keyframes in Luma's Dream Machine. This was the day I've started trying out Leonardo AI as well, so instead of Midjourney, I've generated my images there.
Since both Lumalabs and Leonardo AI offer free trial (Luma has free tier, actually), anyone can try and make a similar video for free.
My image prompt and outputs:
A young woman with striking red hair emerges from the water at twilight, her wet hair clinging to her face. The camera captures the serene, reflective surface of the water and the soft, muted colors of the fading light. Tiny droplets of water glisten on her skin as she gazes intensely into the camera, creating a mysterious and captivating atmosphere.

I then selected 3 most similar looking images and sorted them with motion in mind: from the girl being further away and more submerged in the water, to her standing closer with more of her shoulders visible. This became video plan:

As you might notice, the girl on the first image has a pimple on her right cheek, lol. Actually, problem I came across on Runway's generation for the same prompt as well. But I'll talk about this later in my post on visual AI's peculiarities. For the purpose of my video, I've just retouched the image myself in Gimp:

So anyway, how many video clips do you have to make in Luma to connect 3 images into a smooth transition video?
Only two. Image 1 + Image 2, then Image 2 + Image 3.
In practice though, it sometimes means several attempts until you get it right. But as you get better with prompting, the number of successful generations vs glitchy unusable ones actually goes down, even though sometimes Luma still just gotta do something odd once in a while, being a new tech and all.
But here are the prompts and settings that worked for me for this particular video generation.
Keyframe 1 to Keyframe 2
slow-motion zoom out with a slight upward tilt as the girl slowly comes closer
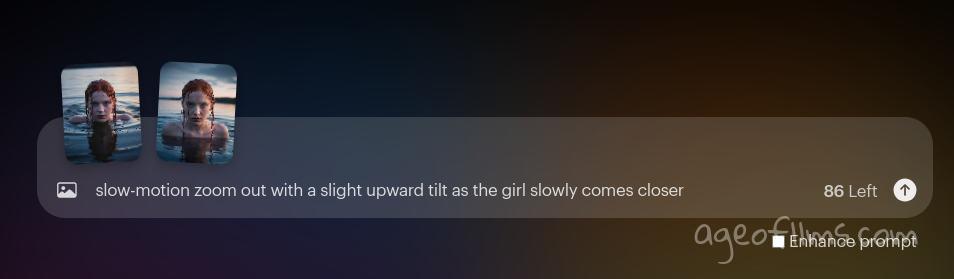
This prompt describes precisely what camera is meant to do during the whole transitioning from frame 1 to frame 2. It also covers what the subject is doing: she comes closer to the camera. Since I've given AI plenty of info of what's going on motion and camera movement wise, I can uncheck the 'Enhance prompt' as it sometimes adds additional effects that might be unwanted. On the other hand, sometimes just leaving everything for the Dream Machine to figure out is the simplest solution, and you can simply upload your images and leave that box checked and leave text field empty, like so:

This generation yielded practically identical output. That is not always the case, but especially if you're just starting to learn how to prompt, and you're impatient to get your first amazing videos done, you might want to try if it just works with least efforts. But in the long run, I think knowing how to describe what you want it to do is beneficial.
So we got our first video, onto the next, connecting Image 2 with the last one.
Keyframe 2 to Keyframe 3
Here is where reliance on the automatic 'Enhance Prompt' didn't work out. AI generated unusable output . Somehow it decided to tilt the camera down on the 1st frame and then just show the next frame without any transitioning or morphing of characters. That's where you want to be able to guide Dream Machine, using a prompt like this:
slow-motion zoom in with a downward tilt as the girl slowly comes closer
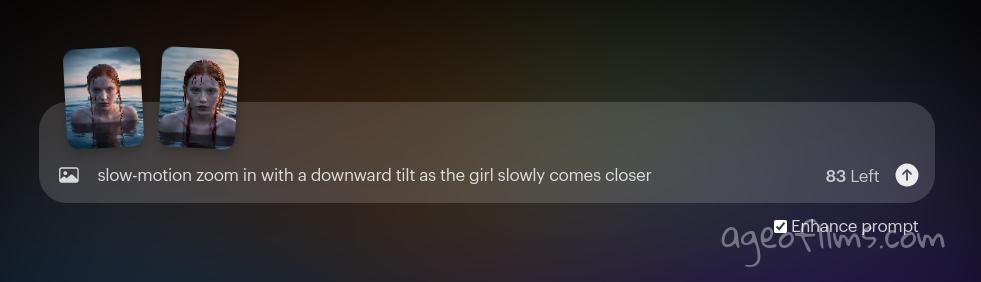
Again, we're describing what camera is doing and what our character is doing. Slow-motion helps emphasize the smoothness of movements, nice and easy, with a bit of cinematic drama atmosphere. As you can see, 'camera tilt' movement is being specified, because look at the horizon: it's visible on the first image and gone on the next. means the camera is aligned straight on the first one, and is facing water on the second, being angled down.
If you're having trouble crafting your prompts for Lumalabs Machine, and you have ChatGPT Pro plan, you might want to check out this custom GPT I've made that helps with that.
End Result: Joining Two Luma Clips
Use your preferred video editor to throw the two clips together and save the result.
Luma Dream Machine Video from 3 Keyframes
Here is what my short video made from 3 images looks like in the end, after I've joined the 2 Luma clips and added ElevenLabs sound effect to it.
Obviously, there are stil improvements to be desired in the video AI tech. Sometimes it does a lot of blurring to conceal its detail-lacking motion animation. Although when you use extremely high quality images as keyframes, high resolution usually translates into a higher quality animation of them, but takes a lot of time to process. So if you're just trying, testing, learning, i recommend using smaller resolution pictures, without any upscaling, to simply see if you got camera and motion control right. Images for this video were only 1024 x 1024 pixels, this is a very basic size. You can generate those on a free plan at Leonardo AI.
Hope this post was helpful, tried to keep it short. if you have any questions or tips of your own to share please leave a comment!
Last modified 03 September 2024 at 08:55
Published: Jul 15, 2024 at 10:54 AM