F5-TTS State-of-the-Art Open Source Text-to-Speech Model
A new TTS model, F5-TTS, launched two weeks ago, so I finally gave it a try.

F5-TTS is an open source text-to-speech model which generates natural and expressive speech, by using sample audio of a few seconds, containing your own or somebody else's voice.
This advanced model with 335 million parameters handles English and Chinese voice synthesis, with more languages on the way. It’s trained on an enormous dataset of 95,000 hours and runs on 8 A100 GPUs, a process that took just over a week.
- HF Space: https://huggingface.co/spaces/mrfakename/E2-F5-TTS
- GitHub: https://github.com/SWivid/F5-TTS
- Demo: https://swivid.github.io/F5-TTS/
- Weights: https://huggingface.co/SWivid/F5-TTS
The performance is impressive, and big thanks to the developers for releasing it as free, open-source software. I’ve tested it with my own voice and some public-domain movie actors. The results are remarkable. F5-TTS and its earlier version, F2-TTS, both have their unique qualities: F2 has a more consistent tone, giving it a formal vibe, but F5 adds that lifelike spark.
BTW, to remove any foreign noise from old movie voices, you can still use ElevenLabs' voice isolator.
I’m still experimenting with different inputs, trying out punctuation, pauses, pitch, and more. I also use Audacity—a fantastic free tool—to adjust tempo and pitch, and if you’re new to it, an LLM can guide you quickly.
I have the software running on my Linux system via pyenv and launch it using python3 gradio_app.py, which brings up the Hugging Face interface (Gradio-based) that many will recognize.
So far, I’ve explored single-speaker TTS and even podcast generation!
F5-TTS Can Do Podcasts
You can create podcasts by uploading two voice samples, naming them, and providing a transcript that calls each speaker.
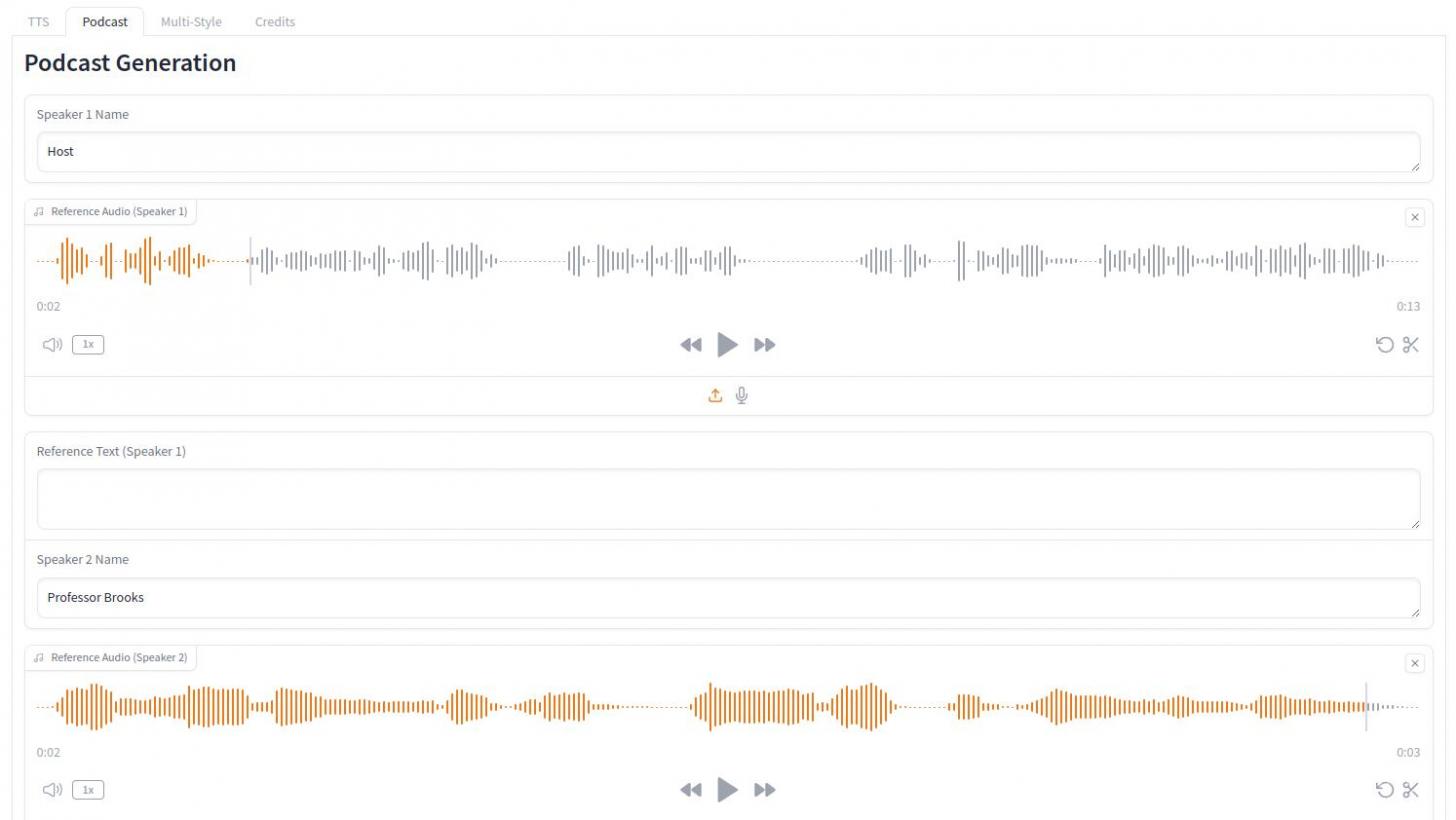
Here’s an example:
Host: "Welcome back to our podcast on the unexpected overlaps of humanity and technology. Today, we explore AI-driven relationships and the emotional impact of sudden digital partner changes. Joining us is Professor Alex Brooks, an AI psychology expert."
Professor Brooks: "Thanks for having me. It’s a modern love story that raises big questions about technology, emotional bonds, and AI relationship ethics."
For podcast generation, I'm finding that it's necessary to 'normalize' both voices, as in, ensure they are on the same level regarding volume, because if they're not equally amplified then the resulting podcast will preserve that. Although maybe there are ways to do that as post-processing.
F5-TTS Podcast Example
F5-TTS can generate great audio for monologues or dialogues, like this podcast.The static video with a waveform was generated with FFMPEG functionality, conveniently implemented by AI Video Composer - all free tools.
F5-TTS VRAM Usage
My system has 16GB VRAM, but for 800-character paragraphs, F5-TTS uses just about 6.4GB—a pretty efficient setup if you ask me. Though I'm not aware of any industry standards for voice related work, I'm just happy I got the hardware for it.
What Redditors Are Saying
Reddit users are excited about F5-TTS for its local, high-quality TTS. Some call it “state-of-the-art” but note limitations like higher VRAM needs (~8GB) and slower processing. Many users have found workarounds, like code tweaks or VRAM management adjustments. Comparisons with models like FishAudio and MetaVoice highlight F5-TTS’s high voice fidelity and unique options like speech inpainting, though it’s reportedly slower than xTTS-v2. Current language support includes English and Chinese, with more expected soon.
Discussions on F5-TTS highlight its voice cloning quality and realism. However, users mention challenges for long-form audio generation, like pacing issues and chunking seams, and slower processing than some models. They’re also calling for friendlier GUIs or Docker support to simplify installation for general users. For handling large text, chunking and concatenation are suggested, though the process is still complex for those without a technical background.
F5-TTS Practical Uses
F5 Text-to-Speech (TTS) solutions have moved beyond accessibility features and are now valuable tools for boosting productivity, accessibility, and user engagement across various industries. For me personally it's of interest in AI short films production and podcasts, but there's many more uses. Here’s how F5-TTS enhances the way we access and experience information:
-
Content Accessibility for Digital Media
- Articles and News: With F5-TTS, articles, blogs, and news can be converted to audio, making it easier for users to catch up on content on the go. The high-quality, natural-sounding voices make hands-free listening more accessible for everyone, including those with visual impairments or reading difficulties.
- Audiobooks: Audiobook production increasingly relies on TTS for cost-effectiveness and on-demand adaptability. F5-TTS’s ability to produce human-like tones makes digital storytelling more engaging and accessible.
-
Enhanced Customer Interaction
- Virtual Assistants and Customer Support: F5-TTS enables virtual assistants to provide more natural, conversational interactions, which can improve customer service in call centers and customer-oriented businesses. TTS voices sound more authentic, enhancing both user trust and engagement.
- Kiosks and Self-service: F5-TTS adds a friendly, accessible touch to automated kiosks in public and retail spaces, guiding customers through interactions with clear, pleasant voice prompts.
-
Productivity and Multitasking
- Document Reading for Busy Professionals: TTS allows reports, emails, and documents to be converted into audio, letting professionals listen while commuting or multitasking. F5-TTS’s adjustable voices help users set the tone to suit either formal or casual content.
- Learning and Education: TTS can assist students and employees by turning textbooks, training content, and online courses into audio, benefiting listening learners and people with various accessibility needs.
-
Language Learning and Pronunciation Help
- For language learners, F5-TTS provides precise pronunciation and adaptable tones, making it a valuable tool for practice and immersion. With multilingual capabilities, it also aids in translation and pronunciation, helping users learn languages more effectively.
-
Gaming and Interactive Media
- TTS in gaming boosts engagement by letting non-player characters (NPCs) interact dynamically with players. F5-TTS gives game characters unique voices, enhancing both character personality and the overall narrative experience.
-
Streamlined Content Creation
- Audiobooks and Voiceovers: F5-TTS technology has transformed the production process for audiobooks, voiceovers, and other audio content. Traditional voiceover work can be time-consuming and costly, involving recording, editing, and re-recording sessions. F5-TTS can generate high-quality, lifelike voices quickly, making production much faster and reducing costs.
- Dynamic Content Updates: For content that changes frequently, like news, instructional videos, or advertisements, F5-TTS provides an efficient way to produce updated audio versions without scheduling new voice recording sessions. This flexibility makes it easier to keep content fresh and relevant.
- Customization for Brand Voice: F5-TTS also allows brands to maintain consistency in their "voice" by customizing tones, accents, and inflections to align with brand identity. This consistency is especially valuable for companies using voice across multiple platforms and marketing channels.
F5-TTS is transforming digital content access with powerful audio solutions that make everyday tasks, media, and interactive experiences more accessible and efficient. Whether in media, customer service, or learning, F5-TTS proves that voice-driven tools are both practical and highly effective.
Last modified 12 January 2025 at 11:44
Published: Oct 26, 2024 at 1:10 PM