Qwen 3 Hits Hard: Alibaba's Open LLM Drop Turns Heads
Qwen 3 Just Landed. And it's bringing serious heat.
- Alibaba releases full Qwen 3 line under Apache 2.0 license
- Models range from 0.6B up to 235B Mixture of Experts
- Small models run well on low-end setups
- Qwen 3 holds up vs LLaMA DeepSeek and more
- Reddit users give mixed but mostly solid reviews
Alibaba’s team Qwen just dropped their full stack of open LLMs. We’re talking everything from a tiny 0.6B model to a beastly 235B MoE version. All under Apache 2.0 so yeah you can pretty much use these how you want. Here's the model on Huggingface. You can try the chat online at https://chat.qwen.ai
Qwen's Full Lineup
- Qwen3-0.6B. Pocket-sized but still capable
- Qwen3-1.7B. A small step up
- Qwen3-4B. The lightweight worker
- Qwen3-8B. Handles decent complexity
- Qwen3-14B. Versatile enough for creative stuff
- Qwen3-30B-A3B. A Mixture of Experts model using 3B at once
- Qwen3-32B. Dense model with strong results
- Qwen3-235B-A22B. Mega model using 22B active parameters
All models are trained and tuned to follow instructions and can handle up to 128K context. Even the small ones hold their own in logic basic coding and storytelling.
Who Should Pay Attention?
If you're into running LLMs locally this is for you. Hobbyist coder or researcher these models work in setups like LM Studio text-generation-webui and Ollama. Even better the sub-4B ones don’t need fancy GPUs so perfect for light gear or edge devices.
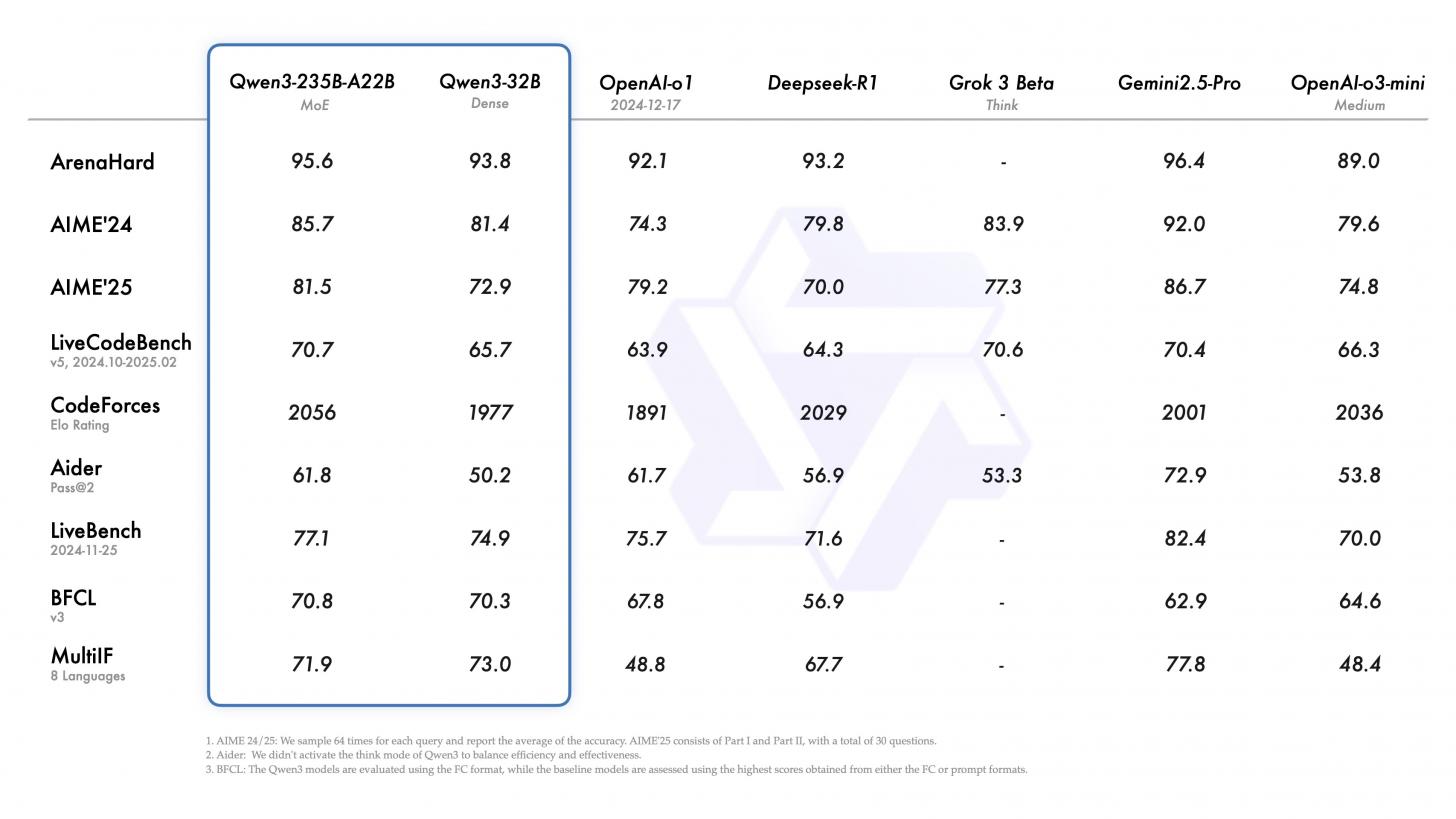
How Does Qwen Stack Up?
Vs LLaMA. Similar build but Qwen models are more open and sometimes handle longer context better
Vs DeepSeek or Mistral. Benchmarks say Qwen 32B thinks well but DeepSeek V4 and GLM4 might beat it in coding
Vs Gemini 2.5 Pro. Not really fair since Gemini’s a cloud-only beast but yeah Qwen still can’t touch it on deep tool use
Local Run Tests and Ollama Drama
Can you run Qwen3 on Ollama? Kinda. It works but not without some rough edges. People on Reddit say they’ve had:
- Weird cutoffs
- Too much “thinking” before answering
- Models ignoring the full context window
Some tricks help:
- Set context to something like 8192 manually
- Use /no_think in system prompt to shut down extra fluff
- Try Unsloth versions for smoother runs
LM Studio and text-generation-webui handle Qwen more smoothly especially the 14B Q4_K_M flavor.
Qwen versions 4B, 8B, 14B, 32B and 30B-A3B are good for laptops with LM Studio.
And you can run smaller models like 0.6B and 1.7B on your phone locally with PocketPal.
Real Talk from Reddit
Here’s what the /r/LocalLLaMA crowd is saying:
- Qwen3-0.6B. “Great for its size” one user said. It’s doing NPC logic and basic stuff better than expected
- Qwen3-14B. Creative enough solid coding just not as good as Gemma 3 in translating
- Qwen3-30B-A3B. Super fast not super smart. Think of it like smart autocomplete
- Qwen3-32B. A lot of folks are calling this their new fave
- Qwen3-235B-A22B. Mixed reviews. Some say it flops on math and code. Might be limited by how it was fine-tuned
Final Thoughts
Qwen 3 looks like it isn’t a hype drop that fades out next week. It’s a real player in the open LLM world especially for folks who run things local. Strong logic long context and solid efficiency in the 30B and under range. Just know you might need to do a little tweaking.
Wanna try something new outside the usual names? Qwen 3 might surprise you. The 32B model might be the sweet spot if you want power without all the hassle.
Published: Apr 30, 2025 at 1:46 PM