Apple Thinks AI Isn't Actually Thinking
Apple tested AI models with new puzzles to dodge memorized patterns
- Models failed completely once puzzles got harder
- Even with step-by-step help they quit early
- The study says these models match patterns not actually reason
- Forum users say we need better training and better ways to test AI thinking
Apple just dropped a study calling out popular AI models for faking it. Not in a clickbait way either. They tested models like Claude Thinking DeepSeek-R1 and o3-mini using puzzles the bots had never seen. Not reused benchmarks. New stuff. And the results? Ugly.
Once the puzzle got even a bit tricky the models crashed to 0 percent accuracy. Not low. Zero. Even when given unlimited compute they started using fewer tokens and just bailed. Like giving up halfway through a riddle.
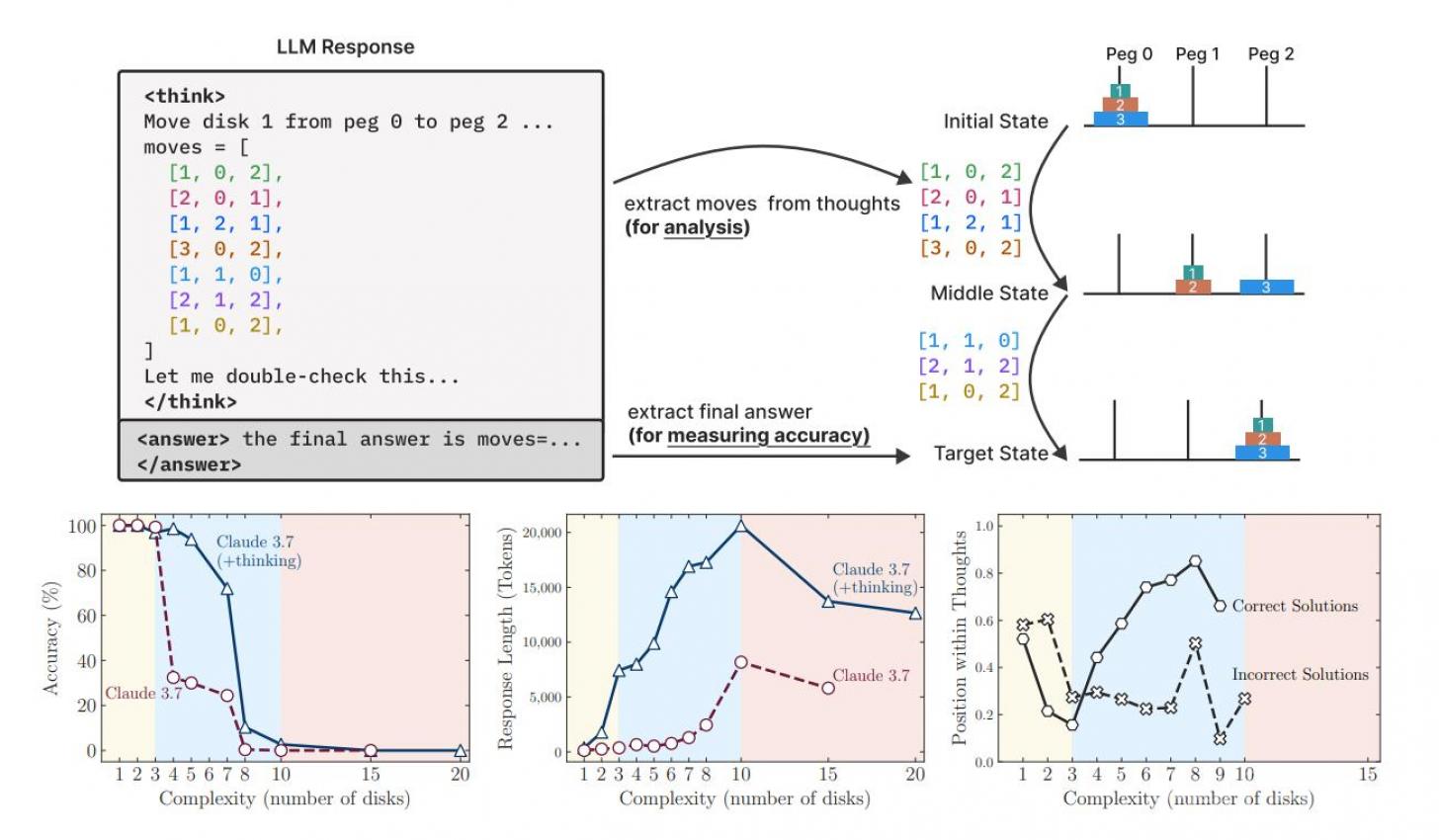
You’d think step-by-step help would fix that right? Nope. Apple tried giving them full solution algorithms. Still failed when the task got too tricky. They couldn’t stick with it or follow through.
Three Types of Problems. All bad news.
They broke it down like this:
- Easy stuff. Simpler models actually did better
- Medium range. Some of the “thinking” ones helped a bit
- Hard problems. All of them collapsed completely
So what's that mean? These bots don’t really think. They just pattern match. When the patterns don’t fit they flail. The moment things go off-script the whole thinking act breaks.
What the Internet Thinks
The forum chatter at Reddit lit up after the paper dropped. Most folks weren’t shocked but it gave them ammo to say what many already believed.
A lot of users said what Apple found lines up with what they’ve seen. These AIs do fine when problems follow familiar setups. But when stuff changes they break fast.
Some even said the whole way we test AI is flawed. Benchmarks only care about the right answer not how the model got there. One post said benchmarks reward “cheating” basically.
And about those token issues? A few folks guessed maybe the models are budgeting tokens weirdly or getting confused by long prompts.
Plenty of people also made peace with it. Maybe the bots don’t think like us but they’re still useful. One post compared it to using Stockfish for chess. The tool doesn’t “think” but wins a lot. Isn’t that enough?
Same goes for humans using tools. Who cares if the machine doesn't reason like a person if it gets results?
Some users brought up new ideas like teaching models to know when to push through or back off. Like training them with some kind of “self-awareness” of difficulty.
Others suggested adjusting how CoT (Chain of Thought) training works. Reward effort when tasks are solvable but hard. Penalize overthinking or just bailing for no reason.
Bigger picture?
Even if these models get good at using tools it’s not the same as real flexible thinking. Real AGI will need something more. One that can roll with weird new rules. Some users said we should track how models solve stuff not just if they get it right.
Not everyone took the paper at face value. A few said maybe Apple is just setting the bar low before WWDC. Keep expectations down. But others noted Apple publishes research all the time so it might not be PR spin.
This isn’t about proving AI can’t think. It’s more like showing current models don’t do it the way some folks claim. They look smart when problems are simple or familiar. But real thinking? That’s still way off.
As one forum user said it best:
“Maybe the question isn’t ‘Is it reasoning?’ but ‘Is it useful intentional and aligned with the human in the loop?’”
Published: Jun 8, 2025 at 7:08 PM
Related Posts

DeepSeek-R1: Open-Source Reasoning AI
21 Jan 2025