DeepSeek-R1: Open-Source Reasoning AI
Key Points:
- DeepSeek-R1 rivals OpenAI's o1 and even beats it in benchmarks like math and coding.
- The model achieves advanced reasoning through reinforcement learning (RL), skipping supervised training.
- It’s open-source and 90% cheaper than o1—groundbreaking shift for AI accessibility.
- Smaller distilled versions perform well while being resource-efficient.
- DeepSeek-AI’s RL-only approach proves big models don’t need constant labeled data to keep improving.
- Website & API are live now! It is available at https://www.deepseek.com
DeepSeek-R1: An Open-source Reasoning Model
So, a fully open-source reasoning model as good as OpenAI's o1 just dropped. It’s called DeepSeek-R1 and it’s honestly wild.
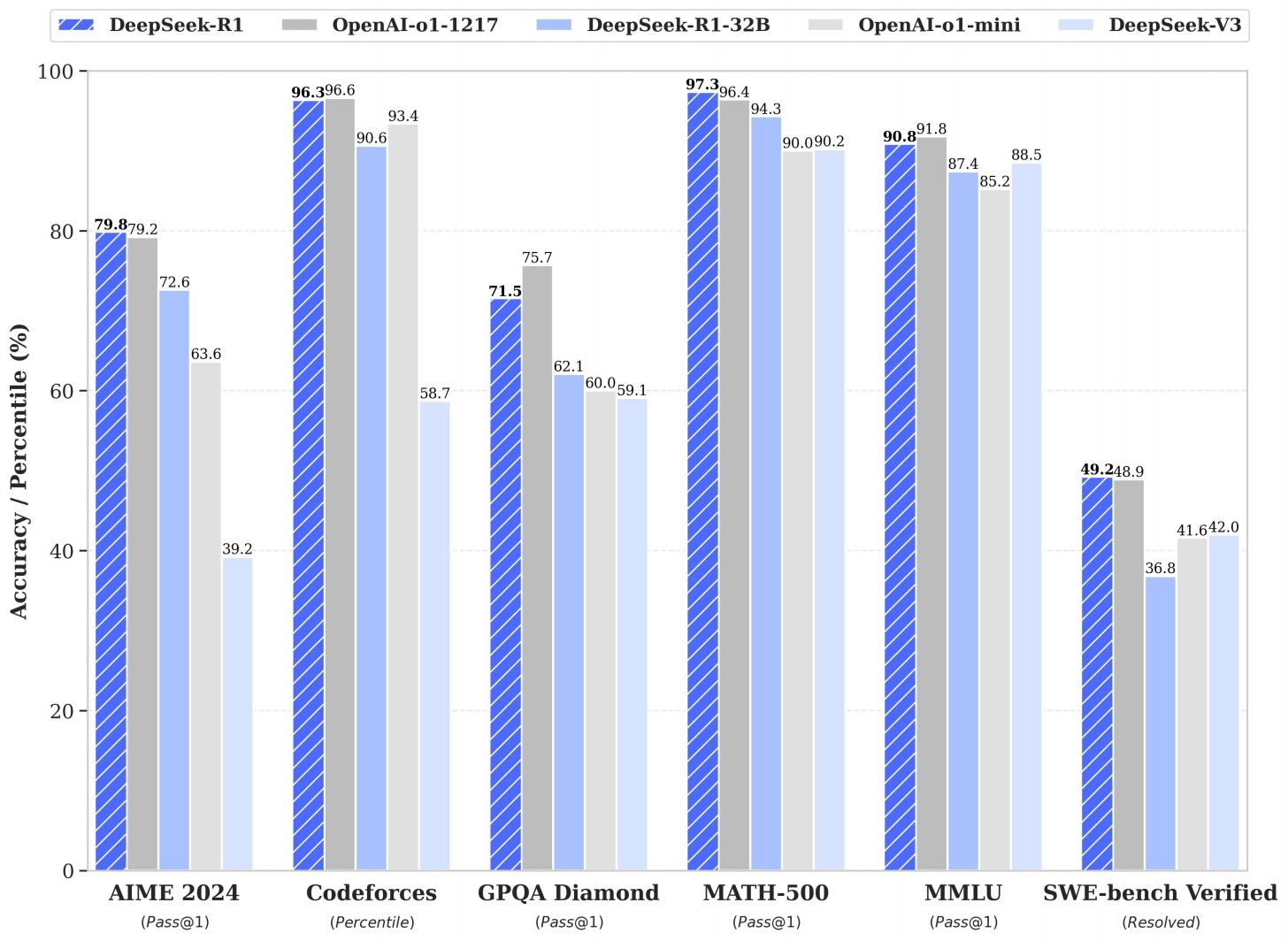
According to its paper this thing matches or beats o1 in key benchmarks like math (97.3% accuracy) and coding (96.3% percentile in Codeforces). And get this—it costs just 10% of what o1 does. That’s 90% cheaper!
What’s the Big Deal?
Here’s the kicker: the paper says DeepSeek-R1 is the first big AI to prove you can teach advanced reasoning through reinforcement learning (RL) alone. No need for tons of hand-labeled “right answers” upfront. The AI just teaches itself by testing how well it’s doing and adjusting. This flips the script because it means AI models don’t rely on labeled data to keep learning.
Because some experts always worried that AI would hit a ceiling because we’d run out of labeled data. But now it looks like AI can skip that step and still improve. Faster, smarter and way more flexible.
DeepSeek-R1’s impact isn’t just technical—it’s strategic. If this tech keeps improving, we’re looking at a shift in global AI innovation. China, or anyone with resources, could create competitive models without waiting for a labeled data goldmine. We’re talking about a new race in AI smarts, with economic and security implications for everyone.
Breaking Down DeepSeek-R1
-
Two Versions:
- DeepSeek-R1-Zero: Pure RL, no training on labeled answers.
- DeepSeek-R1: Starts with RL, then uses a bit of pre-labeled data to clean up readability.
-
Distilled Models:
They’ve squished the big model’s skills into smaller versions (as small as 7B parameters), so you get top-tier reasoning without needing a supercomputer. Even smaller distilled versions—like the 7B model—can match the performance of much larger proprietary systems.And users are already impressed:
“DeepSeek R1 Distill Qwen 7B nailed a hard math problem in one try, thinking through ~3200 tokens in just 35 seconds on an M4 Max.” – Awni Hannun @awnihannun
-
Open Source
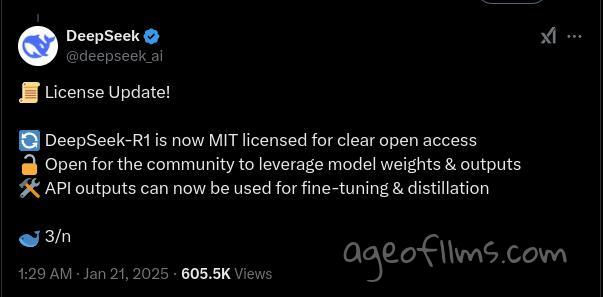
DeepSeek model is MIT Licence It’s all on GitHub—accessible, transparent, and ready for researchers or startups to use. Model on HuggingFace https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1 crushes tasks in:
- Math and Coding: Nailed tough questions and problem-solving challenges.
- Education: Handles factual Q&A like a pro.
- Creative Outputs: Summaries, writing, and visual explanations like the Pythagorean theorem.
What People Are Saying

Folks are already blown away:
“We now have a 30x cheaper o1-level model.
It’s only been a few months since o1 was announced.
AI continues to move at an insane pace.”
Paul Couvert @itsPaulAi:
"Speed is extremely impressive. So far, the most amazing reasoning model I've seen"
elvis @omarsar0:
"The previous preview model wasn't able to solve this task. DeepSeek-R1 can The previous preview model wasn't able to solve this task. DeepSeek-R1 can solve this and many other tasks that o1 can solve. It's a very good model for coding and math."
- @christiancooper: “I asked #R1 to visually explain the Pythagorean theorem. It nailed it in one shot—under 30 seconds!”
-
- Reddit u/ResidentPositive4122: “Distilling competitor models is genius. It shows how good the big model is if the simplified versions are this strong.”
- Reddit u/Zalathustra: “Model distillation helps smaller models act like bigger ones while using fewer resources. It’s smart tech.”@emollick: “The raw chain of thought from DeepSeek is fascinating—really reads like a human thinking out loud.”
- @mihai673: "DeepSeek R1 gets 90.2% on HumanEval tests, running locally on a 3090 GPU. That’s 6% better than GPT-4 last April."
- @AnyOne1725850: "China knows they can’t scale like the US, so they’re pivoting to innovative solutions instead."
Some users are worried it’s not as "open" as it seems. There’s talk of a censorship layer that might lean toward Chinese government guidelines. It’s a reminder to take a closer look at what’s influencing the outputs.
In the video 'Nothing Much Happens in AI, Then Everything Does All At Once', the channel "AI Explained" covers nine big updates in AI from the past 100 hours, including DeepSeek R1. China’s model delivers high performance at a lower cost. While not fully open-source, its development sped up thanks to U.S. chip sanctions.
Especially with models like DeepSeek, people in the field are getting nervous about AI rules ad there’s no clear plan for keeping them in check.
DeepSeek R1 uses a mix of examples, reinforcement learning, and tweaking to teach itself instead of relying on hardcoding.
DeepSeek R1 does well on the "Humanity's Last Exam" benchmark, but its hidden-knowledge focus doesn’t fully show how it’ll work in real life.Nothing Much Happens in AI, Then Everything Does All At Once
When it rains, it pours. OpenAI Operator tested and reviewed, with full paper analysis. Perplexity Assistant is useful. Then Stargate, is it all smoke and mirrors? Strong rumours of an o3+ model from Anthropic. Then a full breakdown of Deepseek R1, and what it’s training method says about the state of AI. It’s not open source BTW. Plus Humanity’s Last Exam, and Hassabis Accelerates his AGI timeline.
With its open-source setup and groundbreaking performance, DeepSeek-R1 feels like it’s just getting started. If you’re into AI, this is one to watch.
Last modified 25 January 2025 at 12:43
Published: Jan 21, 2025 at 12:02 PM
Related Posts

Apple Thinks AI Isn't Actually Thinking
8 Jun 2025