Hailuo AI Video Minimax Tutorial
Hailuo AI Video website can be found at https://hailuoai.video

It is still very early times to be talking about definitive guides, but many people are wondering how to use this powerful text-to-video model, and I've done a lot of testing since Hailuo Ai was released, and also analyzed other peoples experience which they've shared on Discord and Reddit, so here are some of my observations so far, to be updated later once the official guide is realeased and/or I gather more information.
Hailuo AI Prompt Structure
People love prompt structures. I can give you a couple of formulas if you prefer to rely on them, but there are many ways you could prompt this model and get consistantly great results.
First of all, for the complete noobs out there, even if your prompt is just 'Man exersising in a gym', or even just 'Man exercising' - it's stil going to work, but you're just leaving a lot of creative freedom for Ai to make up all the details itself. So there is no mandatory requirement for you to specify camera shot or angle or scene description or lighting or any of that stuff. But you can.
For those wanting to create a series of consistent character/environment (to the extent that it's possible) of course need to provide as much information as possible.
So here is the suggested structure just to highlight all the elements you could include into your prompt:
Let's break down each component:
- Camera Shot + Motion: How the camera frames the scene and how does it move (e.g. Wide establishing shot, tracking the person ...)
- Subject + Description: The main focus of your video (e.g., people, animals, objects). Details about the subject's appearance and posture
- Action: How the subject acts, or what's happening
- Scene + Description: The environment where the action takes place
-
- Lighting: The type and quality of light in the scene
- Style: The artistic approach or visual aesthetic
- Atmosphere: The overall mood or feeling of the video
Again, don't stress if you're not sure what kind of camera shot or movement you prefer or which style or lighting. Concentrate on conveying the subject, action and the overall emotional context of your prompt. From there AI can typically infer the rest. You can make use of the prompt enhance feature offered on the platform, when your prompt is quite basic.

Otherwise you can ask your preferred LLM chatbot to enhance it for you.
The prompt elements can appear anywhere in the prompt. They can also re-appear as needed. For example, you start with the wide shot, and in the middle of the prompt you direct camera to close up on the subject's face, and you also change the lighting to emphasize the facial expression, and in the end your camera pans left to reveal an unexpected element. So it's all flexible.
You can also use diferent prompting styles.
HailuoAI Understands Various Prompting Styles

You could use a declarative style:
The scene opens with a wide over the shoulder shot of a lone woman with extremely long wavy red hair, dressed in tight silver clothes, standing at the edge of the shore, the wind whipping around her, billowing her thick long hair. She stands on a desolate beach, the sky a heavy slate-gray, thick with looming storm clouds.
Suddenly, the ocean begins to churn violently, and in the distance, a massive vortex starts to form.
The camera zooms in on the votrex.
The water spirals downward, pulling everything around it into its growing whirlpool. Tendrils of dark mist swirl around the edges, twisting upward like ghostly fingers reaching toward the sky. The wind picks up, howling as debris from the shore—seaweed, driftwood, sand—gets sucked into the vortex.
The camera pulls back again as the vortex reaches the shore. The water begins to rise unnaturally, creating towering waves that freeze in mid-air, suspended for a moment as if time has stopped. The camera pulls back, revealing the full scale of the vortex and the suspended chaos around it, with the lone woman standing resolute in the middle of the swirling storm.
The scene ends with the camera pulling further back, showing the dark clouds swirling in sync with the ocean's deadly spiral, the entire landscape caught in the grip of the growing anomaly.
Or you could try segmented style and incorporate [prompt tags] like so:
[Camera]: Open with a wide over-the-shoulder shot of a lone woman standing at the edge of the shore, her long, wavy red hair blowing wildly in the wind. The camera captures the desolate beach and the heavy slate-gray sky filled with thick, looming storm clouds.
[Subject]: The woman wears tight, silver clothes that shimmer subtly in the low light. Her thick, extremely long hair billows in the gusts of wind as she stares out at the turbulent ocean, her posture steady and resolute.
[Action]: Suddenly, the ocean begins to churn violently. In the distance, a massive vortex forms in the water. The camera zooms in on the vortex as it spirals downward, pulling debris from the shore—seaweed, driftwood, sand—into its rapidly growing whirlpool. Dark tendrils of mist twist around the edges of the vortex, reaching toward the sky like ghostly fingers.
[Camera]: Zoom in closer as the wind howls, pulling debris into the vortex. The scene intensifies as the camera captures the swirling chaos.
[Action]: The vortex continues to grow, reaching the shore. The water rises unnaturally, forming towering waves that freeze mid-air as if time has stopped.
[Camera]:The camera pulls back, revealing the full scale of the vortex and the suspended waves, with the woman standing still in the eye of the storm.
[Scene]: The shot pulls back even further, showing the swirling storm clouds above, moving in sync with the deadly spiral of the ocean. The entire landscape appears caught in the grip of the vortex, the desolation and chaos spread out across the shore.
BTW you don't even need [square brackets], but some people like them, maybe because they're making the text easier to read and to tweak later.
You can also use directional style:
Start with a wide over-the-shoulder shot of a lone woman standing at the edge of the shore. Animate her extremely long, wavy red hair being whipped by the wind, billowing out behind her. Dress her in tight, silver clothes that reflect the muted light of the desolate beach. The sky is slate-gray, thick with storm clouds hanging heavily above.
Suddenly, the ocean begins to churn violently.
Focus on the water as it shifts and roils. Zoom in on the distant horizon as a massive vortex starts to form, spiraling downward and pulling the sea into its dark core. Show debris from the shore—seaweed, driftwood, and sand—sucked into the vortex. Add dark tendrils of mist swirling around the edges, curling upward like ghostly fingers reaching for the stormy sky.
As the wind picks up, intensify the chaos. Animate the howling wind and flying debris, increasing tension as the vortex grows larger.
Pull the camera back as the vortex nears the shore. Show the water rising unnaturally, creating towering waves that freeze in mid-air for a brief moment, as if time has stopped. Make the waves appear suspended, capturing the eerie stillness amid the violent storm.
Reveal the full scale of the scene—the massive vortex spiraling violently, frozen waves caught in mid-motion, and the lone woman standing unmoving at the shore, resolute against the chaos. Show her long hair still flowing in the wind, contrasting her stillness.
End the scene by pulling the camera back even further. Show the storm clouds swirling in sync with the vortex, capturing the full breadth of the destruction and the growing anomaly. The entire landscape is caught in the vortex’s grip, with the ocean and sky locked in the deadly spiral.
Directing Hailuo AI's Focus: Weights, Structure, and Camera Techniques
Any generative AI has attention mechanism. It is built in to pick up on important parts and concentrate on them before the rest of the prompt. Sometimes it's frustrating when the generated results omits important elements or actions, taking too long animating one action and then another action isn't finished etc. If you'd like to control what part of your prompt Hailuo AI is going to give it's special attention to, there are several ways to do it.
-
Start with the key element first. Consider the two identical but differently structured prompts:
Through the window of a dimly lit room, the soft glow of a distant neon city skyline flickers as raindrops patter gently against the glass. In the foreground, a pair of delicate human hands, weathered yet graceful, petting a sleepy kitten, illuminated by the city's ethereal light.vs
A pair of delicate human hands, weathered yet graceful, petting a sleepy kitten. The soft glow of a distant neon city skyline flickers through the window behind them, casting an ethereal light over the scene as raindrops patter gently against the glass.
How prompt structure affects output Either the subjects of the environment description is hitting AI first, and the resulting generation will vary somewhat because of that.
Also, the amount of attention to detail you give towards some element might make it more prominent as AI will be concentrating on drawing it and it might 'think' since you care so much about describing it in details, perhaps it is the focal point of the video. Speaking of which...
-
Explicitly tell AI to focus on something.
Your prompt might be complicated and loaded with various details, but one aspect of it is crucial, or it keeps being misinterpreted or omited by AI. Tell it literally: ''Focus on monkey jumping on the skateboard".
-
Use weights. Enclose imprortant parts into brackets to emphasize them.
Through the window of a dimly lit room, the soft glow of a distant neon city skyline flickers as raindrops patter gently against the glass. In the foreground, a pair of delicate human hands, weathered yet graceful, ((petting a sleepy kitten)), illuminated by the city's ethereal light.
Hailuo AI understands weighted prompts -
Use camera shots and motions.
Tell AI to how to frame a shot (e.g. close-up, wide shot, aerial view) and how to move the camera (zoom in, dynamic tracking shot etc.)
Wide shot of the dimly lit room. Through the window, the soft glow of a distant neon city skyline flickers as raindrops patter gently against the glass. In the foreground, a pair of delicate human hands, weathered yet graceful, petting a sleepy kitten, illuminated by the city's ethereal light. Slowly zoom in on the city skyline behind the window.
Avoiding Cartoon-Style Renderings
Minimax sometimes renders prompts in cartoon animation style. It seems to happen especially when the scenes involve children, children+magic, cute animals, so appear fitting for the cartoon format, or when the model is finding the prompt too difficult to process, as in "tiny figure on a skateboard in a bottle filled with purple liquid flyingin the room amongst holographic energy blah blah blah'. Seriously though, sometimes it does that CGI effect and it's a bit annoying, and so far I only have some observations and intuitions about that.
So how to avoid the forced cartoonish rendering anyway? Ok, here are some suggestions.
First, I can tell you what doesn't really help. It may work just like sheer luck, but so can just trying many times the same prompt. So adding these keywords:
- 'Photorealistic', 'photorealistic high-definition visuals';
- 'Cinematic', 'cinematic shot';
- Mentioning lens types (35mm, IMAX 70mm - will give you a 3D cartoon)
- 'Not cartoon' (AI really hates negatives, you'll just make it worse)
What does help?
1. Weighted style references like (((Cinematic movie style))). Example:
((Cinematic movie style)): A pair of delicate human hands, weathered yet graceful, petting a small, fluffy kitten with blue eyes. The soft glow of a distant neon city skyline flickers through the window behind them, casting an ethereal light over the scene as raindrops patter gently against the glass.
2. Modifying things, associated with children cartoons. Remove bright colors, naive scenarios (girl with pig-tails petting a cute little kitten). Basically, think of children shows, what are they filled with? Vibrant colors, kids, animals, sweet naive funny scenes, magic etc - all these can trigger AI to think your prompt belongs best in the animation category.
I've had this one prompt which came out as cartoon every time. It was about two girls in bright clothes and a kitten (duh). I'm simplifying, but it went in essence like this:
A 10-year-old girl with bright red hair kneels in a grey-toned room, wearing a vibrant yellow dress. She holds an orange kitten, smiling warmly. On the other side, an elderly woman stands in a desaturated park, reaching out with joy toward the girl. The girl slowly extends the kitten toward the center. The kitten's orange fur remains vibrant as it crosses the boundary, and the elderly woman gently takes it, creating a seamless, tender handoff.
I've tried adding all sorts of photorealism references but no luck, even added 'Gothic, contemplative, haunting, moody' - I mean, impossible anyway with those colors, right? But I had to try. So I've decided to modify the color scheme. The following prompt rendered photorealistic straight away:
A 10-year-old girl with dark pigtails kneels in a sepia-toned room, holding a small kitten. She gazes toward an elderly woman in a barren park, her expression somber. The elderly woman, standing near a decayed bench, extends her hands with quiet anticipation. As the girl moves the kitten toward the center, both worlds blur slightly. The woman reaches out, gently taking the kitten’s paw in a tender, haunting moment of connection.

The prompt above involving hands petting a kitten originally had "a small, fluffy kitten with bright blue eyes" in it and it rendered toonish 90% of the time. Even removing the 'small fluffy and bright blue eyes' helped minimise the number of animated style outputs. Bright colors, tiny little cute things - they're triggers, no doubt.
If nothing helps, try adding supporting emotional details. Add serious, adult thoughts/feelings to the picture. Yes, they're invisible on the picture but they help guide AI away from kiddie stuff. This is how I've modified my kitten-petting prompt and started getting mostly cinematic movie renderings:
Through the window of a dimly lit room, the soft glow of a distant neon city skyline flickers as raindrops patter gently against the glass. In the foreground, a pair of delicate human hands, weathered yet graceful, ((petting a sleepy kitten)), illuminated by the city's ethereal light. The hands move with a measured rhythm, fingers gently combing through the kitten's fur. Each stroke is deliberate, almost meditative. The skin is marked with fine lines and a few age spots, telling a story of years lived and hardships endured. A slight tremor in the left hand betrays an underlying tension, contrasting with the soothing motion. The right hand pauses momentarily, fingers curling as if grasping for something intangible, before resuming its gentle caress. The sleepy kitten stretches lazily under the touch, oblivious to the emotional weight carried in those hands. Its contented purr provides a soft counterpoint to the rain's patter. In the background, the city lights waver and dance, casting shifting shadows across the hands. The juxtaposition of the vast, impersonal cityscape and the intimate, caring gesture creates a poignant tableau of solace sought amidst life's complexities.

3. Simplifying your prompt
Try and keep your prompts simple at first. Reduce your prompt to barebones and keep adding details until you find the tipping point of the model and then you know what it might be that's causing that. Or perhaps you'll find that you got the desired output along the way.
Even with simple prompting you can have great control over the video. By stuffing your prompt full of unnecessary words you're making it bulky without necessarily adding much of value as these models are trained to infer from limited information. Even if you won't write '[Start of action]' and '[End of action]' the Ai will guess where the beginning and end of action is. And if you won't literally announce '[Lighting/Mood]:' before mentioning lighting and mood preferences it will figure things out. So save AI attention for things that really matter, such as conveying in plain English what your video is about, trying to paint a coherent full picture, oftentimes including emotions, because they help AI understand the context and as such the meaning of your instructions better.
Hailuo AI Prompts Censorship
HailuoAI Video generator has a built-in censorship system. On the old website, you could go through the whole process of creating a video, only to end up with nothing, or the whole prompt would be rejected without telling you what specific words were unacceptable (like in Kling). On the Minimax's new platform, your prompt still is accepted, but after your video is done generating, it goes into moderation, to ensure it is compliant with the policies. In my experience, anything involving beach, pools, even if no bikinis or swimsuit are mentioned (I actually had a guy in robes jumping in) it will trigger some sort of flags and go under the review for some time. The word 'dirty', similar to Kling AI, has a bad karma. So while the moderation is taking place, you will see somethig like this:
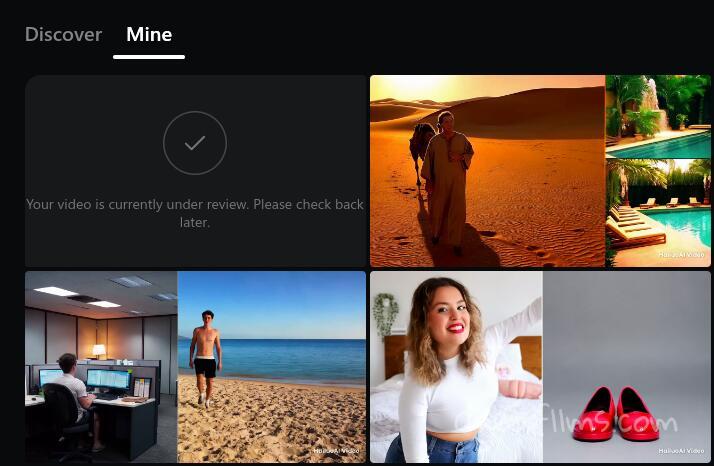
I recommend refreshing that page in a few minutes because right now it doesn't seem to automatically update, so your video could be available but the site doesn't tell you that until you reload the page.
Cool Hailuo AI Prompts to Try
Play around with split-screen videos. As per Hailuo AI team on Discord, you can use this kind of a basic structure:
The scene is divided into two parts, left and right, separated by a boundary. To the left of the boundary is [subject, scene] is moving to the right of the frame. To the right of the boundary is [subject, scene]. Suddenly, the [subject from left] crosses the boundary [what happens next].
Their example:
The scene is divided into two parts, left and right, separated by a boundary. To the left of the boundary is a cat that is moving to the right of the frame. To the right of the boundary is a ruin, and the camera slowly pulls away. Suddenly, the cat jumps up and crosses the boundary, and after doing so, the cat transforms into a huge monster.
After having made dozens of divided scene generations, I can testify this is not the easiest thing to achieve and you will get a lot of results where crossing doesn't happen. You have to have patience.
This was my split-screen video prompt. You can check many more of them in my video here 👉 https://www.youtube.com/watch?v=97MtR1nk_Ew

A split-screen video.
Left: A cheeky, fashionable 20-year-old woman dressed in a white crop top and high-waisted jeans, her hair casually tousled in that effortless, chic style—stands in her stylish bedroom. Without hesitation, she leans eagerly towards the right, eyes already locked on her prize. Her face shows a mischievous grin, brimming with excitement as she leans further into the right side.
Right: In the middle sits a single pair of cute vibrant red shoes. The shoes gleam against the plain backdrop, their glossy, eye-catching design sharply contrasting with the simple grey background.
The interaction or connection between the two sides: The woman wastes no time. She reaches across the screen divide almost immediately, her arm cutting across the boundary. Her hand confidently picks up the red shoes, seizing them with quick determination as if they’ve always belonged to her. She pulls them into her bedroom with a triumphant smirk, her excitement growing as she holds them.
As her arm passes through the screen’s divide, the moment feels fluid and playful. The shoes, once part of the grey void on the right half of the screen, now fully belong to the colorful world on the left half of the screen in the hands of the joyful woman.
After the woman has the shoes on her side of the screen, she immediately starts playing with them, lifting them up, rotating them in her hands, admiring them from every angle. Her expression changes rapidly—from mischievous to pure joy. She inspects the shoes closely, feeling the texture of the material, tilting her head as she thinks how cute they are. At the same time on the right half of the screen there is only an empty grey background.
And here are some of the awesome prompts shared on Discord for your inspiration. Again, we can see that various prompting styles can yield great results.

A woman in pink sweater, blonde hair with a ponytail, has her fingers touching the side of her head as if she is focusing deeply while looking directly at an apple sitting on top of a wooden kitchen counter, and then the apple starts to rise from the counter into the air and it rises up and up and up into the air as the woman keeps looking at it, making it float with her mind.

Frame Styles: Muted earth tones with pops of vibrant color. Layered depth of field. [Parallax Shot] creating a dynamic, multi-plane effect. Scene Description: Foreground: Wooden fence posts, swaying prairie grass. Midground: Wide dirt road with cowboy walking. Background: Old Western town buildings, saloon, bank, sheriff's office. Far background: Distant mountains, wispy clouds. Character Description: Weathered cowboy, late 40s, steely-eyed. Tan leather duster, dark shirt, worn jeans. Distinctive hat with a rattlesnake band. Silver-plated revolver at his side. Action Sequence: Cowboy strides purposefully down the street. Parallax effect causes foreground elements to move faster than the background, creating a sense of depth and movement. Transitions and Effects: Continuous smooth parallax movement. Style, camera type, and lighting: HDR, Cinematic Lighting, 8K, hyper-realism, ultrarealistic, natural, Cinematic Scene, Vivid, hyper-detailing, crisp. shared Leading Lines

The shot opens with an ultra-wide-angle tracking shot, capturing a pretty curvaceous busty young woman covered head to toe in vibrant, psychedelically patterned body paint as she walks slowly through a surreal pastel landscape of rolling hills meadows and forests. The world around her is an eclectic blend of textures: swirling mounds of pastel whipped cream, fluffy cotton balls, and soft, oversized felt shapes. The camera floats slightly above and behind her, gliding smoothly as her every step leaves ripples in the whipped cream-like surface. As she moves, the camera subtly rotates, revealing more of the colorful, dreamlike world that seems to bend and shift like liquid beneath her feet.
Midway through, the camera transitions to a slow dolly-in close-up, drawing attention to the intricate details of her body paint and the soft light around her. The scene feels ethereal, almost weightless, with ultra-smooth motion as the camera moves in sync with her graceful strides. The colors in the environment shift subtly in harmony with her movement, creating a hypnotic sense of flow as she walks through this vibrant, plush landscape.

The scene begins with an over-the-shoulder shot of a man standing still in his backyard, staring at the sky. He’s wearing a faded leather jacket, creases running along the sleeves from years of wear, and his unkempt dark hair is swept up by the gusts of wind. The camera starts low, focusing on his figure as he gazes at something above. The shot pans upward to reveal an ominous wormhole, hanging in the stormy sky, with tendrils of spiraling plasma energy circling its dark, gaping center. The hole pulses, glowing faintly with hues of purple and electric blue that contrast against the swirling, angry gray clouds. The plasma arcs flicker and crackle, lighting up the sky intermittently as they twist around the rim of the hole. Dust and debris from the ground begin to rise, caught in the invisible pull of the wormhole. Leaves, branches, and dirt are sucked up into the air, swirling chaotically toward the ominous void. The camera zooms in on the swirling debris as the wind intensifies, lifting chunks of earth and splintering wood from the nearby shed. The trees in the backyard shake violently, their roots struggling to hold firm against the pull of the vortex. The man stands motionless, watching as the wormhole continues to grow, its energy expanding, causing the air to hum with tension. The camera pulls back to show the full scope of the chaos—debris whirling around the backyard, the sky darkening, and the man standing in eerie stillness as the glowing plasma rings continue to spiral faster around the edge of the wormhole. The scene ends with the camera zooming back out, capturing the full scale of the destruction and the still-growing anomaly.
If you have any questions or tips of your own feel free to share in the comments!
Last modified 25 September 2024 at 08:25
Published: Sep 24, 2024 at 2:50 AM