Mistral drops new AI models optimized for mobile devices
French AI startup Mistral has introduced its first generative AI models designed for edge devices like laptops and phones. This new model family, called "Les Ministraux," includes the Ministral 3B and Ministral 8B models.
These models are designed for various applications, such as text generation, on-device translation, smart assistants, and autonomous robotics, and feature a context window of 128,000 tokens — enough to process the equivalent of a 50-page book.
Mistral emphasizes the demand for privacy-first, local inference solutions, stating that the Les Ministraux models offer compute-efficient, low-latency performance ideal for situations where internet access is limited.
Les Ministraux Availability
Ministral 8B is available for research purposes, though a commercial license is required for wider use, while Ministral 3B is only accessible via their API and isn’t open-source.
Both models are also available through La Plateforme, Mistral’s cloud service, and have been priced at $0.10 and $0.04 per million tokens for the 8B and 3B models, respectively.
Mistral’s models align with the growing trend of smaller, more efficient AI models, competing with offerings like Google's Gemma and Microsoft's Phi collections, and claim to outperform models like Llama and Gemma in instruction-following and problem-solving benchmarks. But sadly, unlike those models, Mistral models, including Ministral 3B and Ministral 8B, cannot currently be run on Ollama. They use a different architecture that isn’t supported by Llama-based frameworks.
Benchmarks
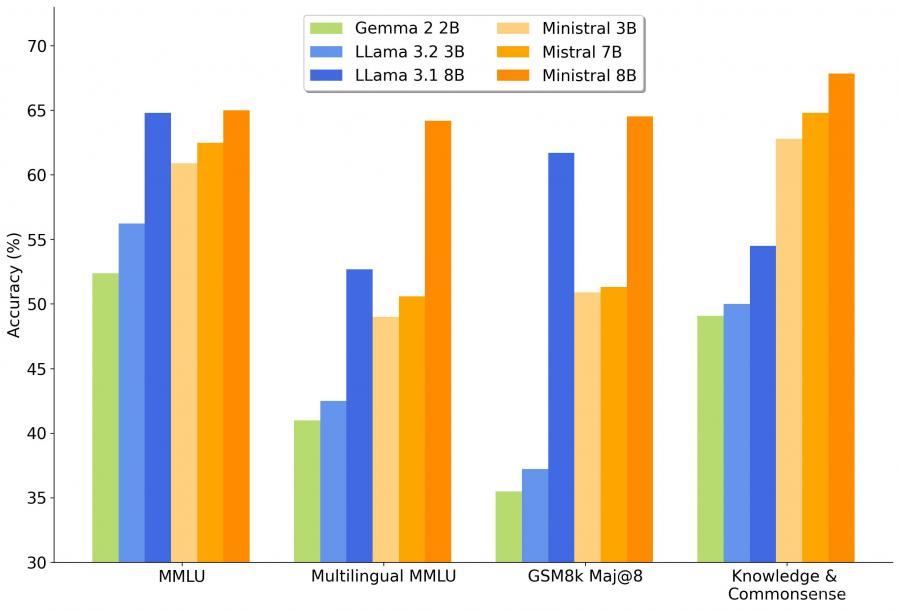
These models are function-calling capable, with Mistral benchmarking the 8B model on par with Llama 3.1 and the 3B model outperforming Llama 3.2. However, there's skepticism about the reliability of these benchmarks, especially the inclusion of a non-standard metric, "Knowledge and Common Sense?"
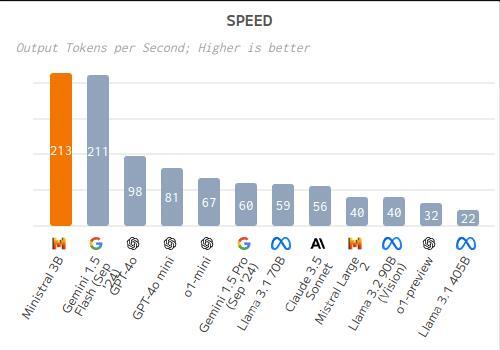
According to independent bechnmarks Ministral 3B :
- is cheaper compared to average with a price of $0.04 per 1M Tokens (blended 3:1). Ministral 3B Input token price: $0.04, Output token price: $0.04 per 1M Tokens.
- is faster compared to average, with an output speed of 213.4 tokens per second.
- has a lower latency compared to average, taking 0.45s to receive the first token (TTFT).
- has a smaller context window than average, with a context window of 130k tokens.
According to the same independent bechnmarks Ministral 8B:
- is cheaper compared to average with a price of $0.10 per 1M Tokens (blended 3:1). Ministral 8B Input token price: $0.10, Output token price: $0.10 per 1M Tokens.
- is faster compared to average, with an output speed of 136.7 tokens per second.
- has a lower latency compared to average, taking 0.44s to receive the first token (TTFT).
- has a smaller context window than average, with a context window of 130k tokens.
The 8B model, which is open-source under the Mistral Research License, shows strong performance, particularly in coding and mathematical reasoning, suggesting it may be a good alternative to Llama 3.1 for personal use.
Community Sentiment
The Reddit discussion on Mistral's new models, Ministral 3B and 8B, reflects mixed reactions. Users are intrigued by the interleaved sliding-window attention mechanism, although it’s not yet supported by llama.cpp. Some are frustrated by the 3B model’s limited availability (API-only, no download), seeing it as a commercial move. There's curiosity around the models' real-world performance but hesitation without benchmarks. Enthusiasts are eager to tinker, but overall, caution dominates due to past release disappointments.
Link to the full discussion: Reddit Thread.
Earlier in September, Mistral introduced Pixtral 12B, a multimodal model that excels in both image and text tasks. It features a new architecture with a 400M parameter vision encoder and a 12B parameter multimodal decoder, designed to handle variable image sizes and long-context windows. Pixtral 12B, available under the Apache 2.0 license, performs well across multimodal and text-only tasks.
Last modified 19 October 2024 at 09:49
Published: Oct 18, 2024 at 5:30 PM