Llama 4 Is Here and It's Not Messing Around
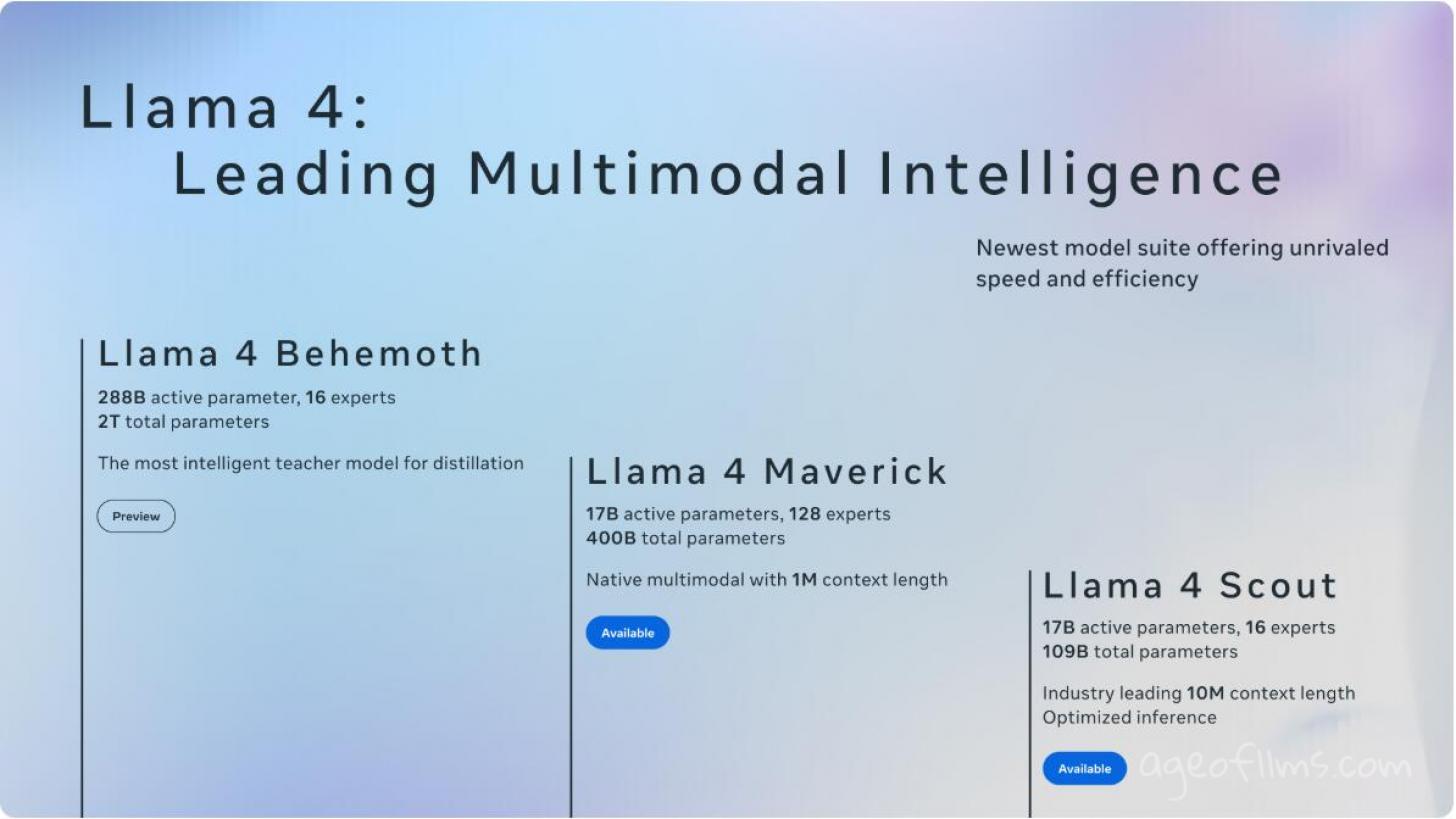
- Meta released Llama 4 Scout and Maverick open-weight models
- Scout runs up to 10 million tokens Maverick hits 1 million
- Behemoth with 2 trillion parameters is still in training
- Mixture of Experts is now standard
- You’ll need a monster GPU to run them locally
- License limits usage by massive companies
Llama 4 is out and yeah it’s a lot. Meta just dropped two wild open-weight models with two more on the way. And the specs are kinda bonkers.
Llama 4 Scout. This thing eats context for breakfast.
- 17B active parameters but behind the scenes it's rocking 110B total
- 10 million token context
- Multimodal—reads text images even full video
- Runs on a single GPU... if you’ve got an H100 with enough juice
- Crazy good at digging up info from massive chunks of data
Not great for coding though based on early benchmarks.
Llama 4 Maverick. This is the beast for regular tasks.
- Same 17B active but 400B total parameters
- 1 million token context
- Also multimodal
- Ranks #2 in Chatbot Arena right behind Gemini 2.5 Pro
- Outperforms GPT-4, Gemini Flash 2, Grok 3 in user votes
And it’s efficient too. Costs less to run than other big names and it’s still a top performer.
Llama 4 is Meta’s first real attempt at what’s called a mixture of experts model—basically the AI is made up of different parts that handle different tasks depending on what you’re asking it to do. At first Meta held the release back because the models weren't doing so hot in math and logic problems but switching to this new mixture setup made a big difference. They’re training these models on a monster setup of over 100,000 H100 GPUs which might be the biggest publicly known group of AI machines anyone’s using right now. As for what the models can handle—Scout can work with inputs up to 10 million words or tokens while Maverick handles up to 1 million. That means they can read and understand a ton of info at once. But there’s a catch. Running these models isn’t something you can just do on a regular laptop. You’ll need at least one high-end GPU like an Nvidia H100 and if you want full performance you might need more than one. The newer B200 GPUs are even faster—they can run Scout nearly three and a half times quicker than an H100 pushing out around 40,000 words per second.
What’s Coming
Llama 4 Reasoning. More logic and problem-solving skills—soon.
Llama 4 Behemoth.
- 2 trillion total parameters
- 288B active
- Not done training yet
- Already beating GPT-4.5 and Claude Sonnet on STEM tasks
This could end up being the biggest base model out there.
So can you use them?
Yep—unless your app has more than 700 million monthly users. Then you gotta ask Meta for permission. And you have to put “Built with Meta” somewhere.
For the rest of us?
- Try them on Meta.ai in Messenger WhatsApp or Instagram or on Replicate
- Use Together.ai or Grok playground
- Download weights from Hugging Face if you've got GPU power to spare
What’s it all mean
- Mixture of Experts is the new default
- Long context is the new flex
- Open weight doesn’t mean totally free—but it’s still way more open than closed labs
- Behemoth might shake the whole leaderboard when it lands
Feels like Meta’s tired of playing second fiddle. They're going big and weird with Llama 4 and honestly it’s working.
Last modified 07 April 2025 at 15:26
Published: Apr 6, 2025 at 8:58 PM
Related Posts

AI Disruption: Job Losses and a Future in Flux
13 Jan 2025

Meta's AI Search Engine Coming?
31 Oct 2024