Liquid AI's new Liquid Foundation Models
Liquid AI has just launched its first series of Liquid Foundation Models (LFMs), marking a new chapter in generative AI. Liquid Foundation Models (LFMs) are a new family of large neural networks developed by Liquid AI, based on a unique architecture different from Transformers.
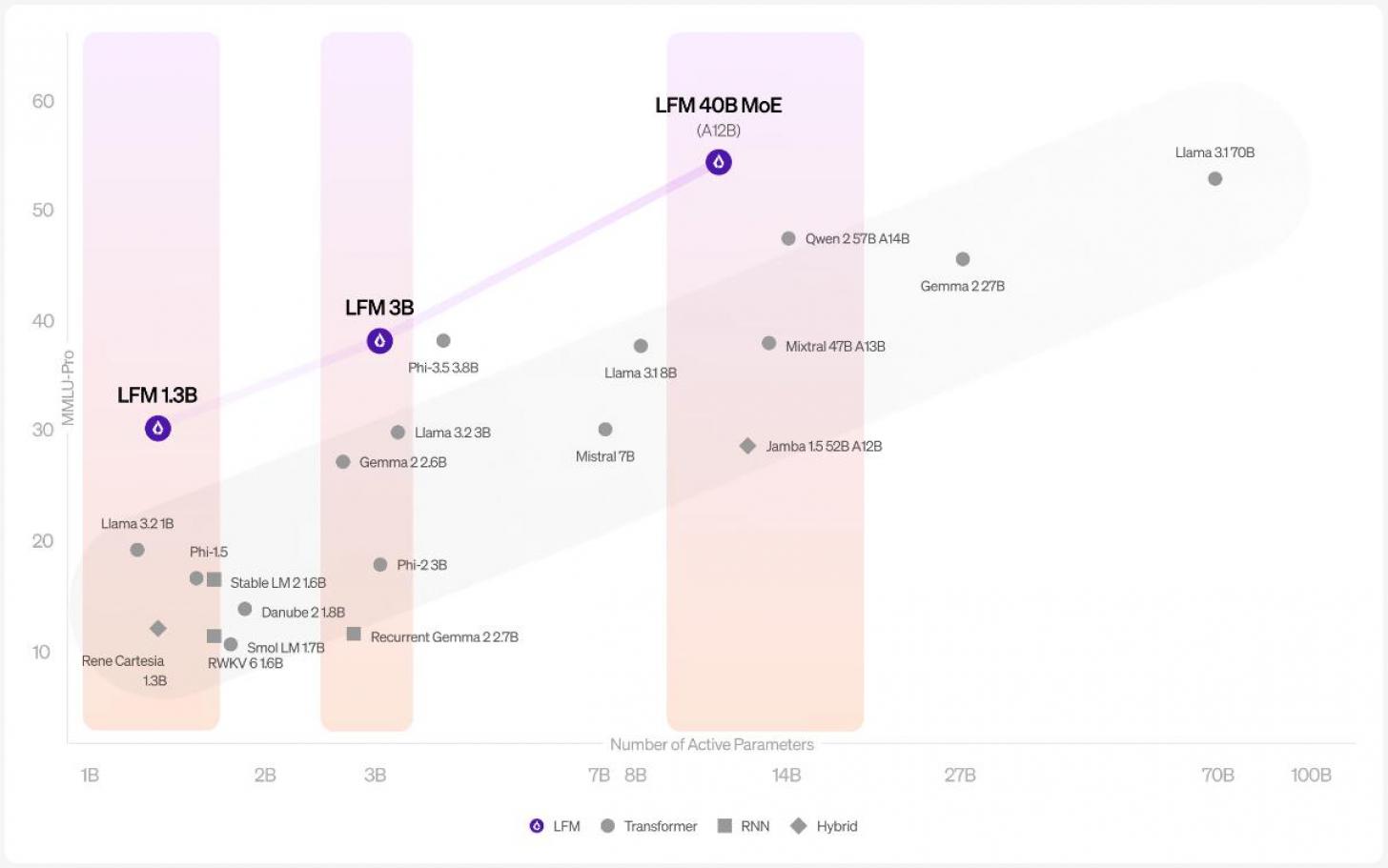
These LFMs come in three sizes—1 billion, 3 billion, and 40 billion parameters—each built to deliver top performance while using less memory. They’re optimized for various platforms like NVIDIA, AMD, and Apple, making them versatile for different setups.
What’s unique about these models is how they’re designed. They’re based on principles from fields like dynamical systems and signal processing, which lets them handle all kinds of sequential data—whether it’s text, audio, video, or time series. This makes them ideal for industries like finance and biotech, offering efficient solutions for businesses of all sizes.
Below is a video from May 2024 of Liquid AI SEO discussing the technology they're working on.
Building More Efficient AI: How Liquid AI Is Working To Optimize AI
Spun out of MIT CSAIL, four founders - Ramin Hasani, Mathias Lechner, Alexander Amini, and Daniela Rus, started Liquid AI with the mission of building state-of-the-art, general-purpose AI systems that are capable, efficient, highly aligned, and trustworthy. On this panel at Imagination In Action’s ‘Forging the Future of Business with AI’ Summit, Hasani and Amina discuss how the company thinks about AI and how they plan to make it more efficient.
.
The 1.3B model is great for environments with limited resources, while the 3.1B model is built for edge deployments, beating out older models in its category. The 40.3B Mixture of Experts model strikes a balance between size and quality, ensuring high throughput on cost-friendly hardware. Liquid AI says their models not only perform well but also have a smaller memory footprint compared to traditional transformers. This means LFMs can handle longer inputs without using up a lot of memory or increasing processing time.
The highlight is definitely the 40B model. It scored 55.63 on the MMLU Pro benchmark, surpassing other models like Jamba (28) and Mixtral (47). This is a big deal since it’s only the first-gen model, but it’s already competing with well-known names in the field.
These results show the 40B model is strong in tasks like reasoning, language, and math—although math is still a challenge for most AI models. This shows that Liquid AI’s architecture is effective at getting state-of-the-art results while keeping things efficient. If these models continue to develop like this, they could potentially surpass the popular Transformer models.
One more standout feature: LFMs are designed to support a context length of 32k tokens. That makes them perfect for complex applications like document analysis or smarter chatbots. Liquid AI isn’t open-sourcing their models right now, but they’re still sharing findings and working with the AI community.
If you want to see what’s next for Liquid AI, they’re hosting an event on October 23rd, 2024, at MIT Kresge in Cambridge, MA.
You can try the model yourself right here.
So far we're waiting to see real-life tests and independednt reviews of the new product to verify the impressive benchmarks posted by the company.
Published: Oct 3, 2024 at 9:24 AM