ARIA - New Open-Source AI Drops
Rhymes AI just launched Aria, the world’s first open-source multimodal Mixture-of-Experts (MoE) model. Based in Sunnyvale, CA, the startup promises Aria will boost performance across text, images, videos, and code without needing multiple specialized models.
The company seems to have sprung up out of nowhere, with its X followers count just over 1K (including myself now).

- Demo: https://rhymes.ai/
- GitHub: https://github.com/rhymes-ai/Aria
- HuggingFace: https://huggingface.co/rhymes-ai/Aria
- Technical Report: https://arxiv.org/pdf/2410.05993
Key Features
Aria’s standout feature is its efficiency. Using a MoE structure, the model only activates part of its parameters per token, which speeds up processing and lowers costs compared to fully activated models like Pixtral-12B or Llama-3.2-11B.
Aria has a total of 24.9 billion parameters, but only uses 3.5 billion activated parameters per text token and 3.9 billion parameters for visual tokens, while other models activate over 12 billion visual tokens.
Benchmarks show Aria competes with, and sometimes outperforms, models like GPT-4o mini and Gemini 1.5 Flash, especially with long videos or multi-page documents.
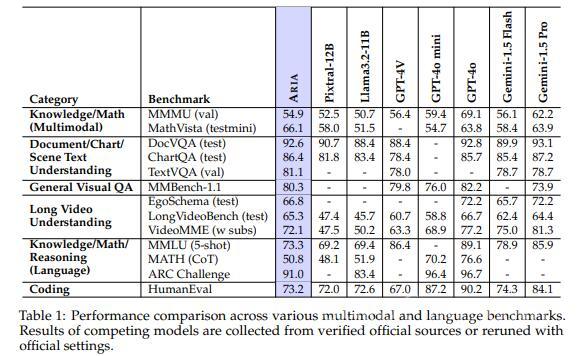
But, since the company reported these results, experts say third-party tests are needed to verify its superiority in every task.
One of Aria’s strengths is its ability to handle large amounts of data—up to 64,000 tokens at once—making it ideal for long videos or big documents. As an open-source model under Apache 2.0, developers can also tweak it for specific needs, potentially widening access to AI.
Rhymes AI teamed up with AMD to fine-tune Aria for AMD hardware, highlighting real-world uses like AI search engines. But again, most of the benchmarks come from Rhymes AI itself, so independent reviews will be crucial to confirm these claims.
Early Feedback
Online discussions on Reddit show users are intrigued by Aria’s open-source design and multimodal abilities. Many are excited about its potential to handle different inputs like text, images, and video, but some are waiting for independent testing. Some users also plan to experiment with it on Hugging Face and compare it to popular models like GPT-4. Aria’s parameter efficiency and lower costs are winning points, but the hype might need to be tempered until more real-world tests are in.
One user on X shared their excitement about testing Aria’s text, image, and video skills. They found it especially good at debugging code from screenshots and reading even difficult handwriting. Aria also showed strong document understanding, all without needing complex prompts. The open-source setup and ease of use on Hugging Face were bonuses. You can check out the full thread here: https://threadreaderapp.com/thread/1844356121370427546.html?utm_campaign=topunroll.
Some people mention that the base model of Aria hasn't been released, meaning that the core version of Aria—without any fine-tuning or specific adaptations—isn't available for general use yet. This could limit developers who want to train or modify it for their specific applications, as they need access to the base model to make custom adjustments. Essentially, without the base model, users can’t perform in-depth experimentation or customization beyond what’s available in the pre-trained versions currently provided.
My Quick Tests
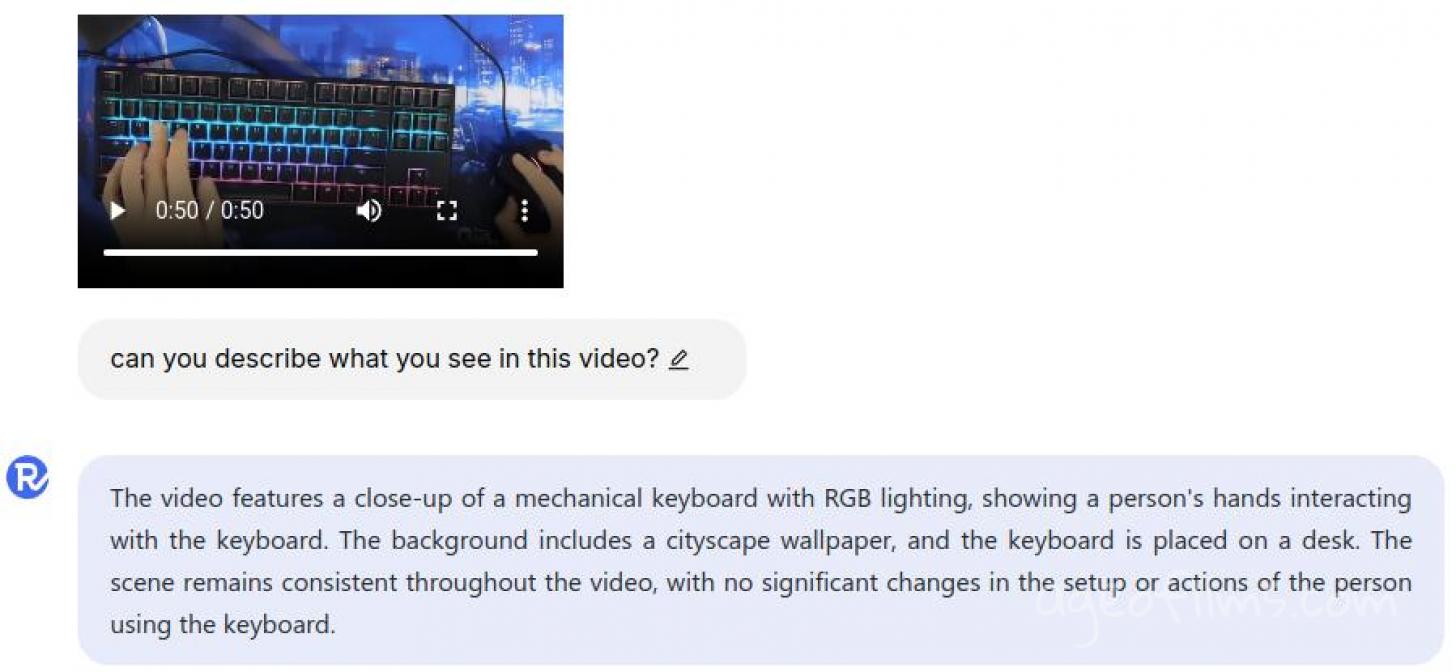
I’ve also tested Aria’s video analysis on their site, uploading two stock videos — one realistic, the other more abstract. Aria gave quick and accurate descriptions in both cases. It seems like Aria analyzes key frames to get a fast understanding of the context, making it useful for video-related tasks.

It seems that despite its 24.9 billion parameters, the average user won’t be able to comfortably run Aria locally unless they have access to powerful hardware, like an A100 (80GB) GPU. This means it’s limited to a select group for now. But, if a smaller version is released, it could open the door to wider use and testing. Independent reviews will be crucial to see if Aria lives up to the hype.
In summary, Aria looks very promising, but its early days, so we'll see. 👀
Published: Oct 17, 2024 at 10:51 AM