Agent Leaderboard: How AI Agents Stack Up in Real-World Tasks
Elvis, known on Twitter as @omarsar0, has shared that Galileo AI just dropped the Agent Leaderboard—a way to rate 17 top AI models across 14 varied datasets. It checks how well they handle tool-calling tasks, which matter a lot when building AI agents:
"Introducing... Agent Leaderboard!
Many devs ask me which LLMs work best for AI agents.
The new Agent Leaderboard (by @rungalileo) was built to provide insights and evaluate LLMs on real-world tool-calling tasks—crucial for building AI agents."
The Best Model.
Google's Gemini-2.0-flash leads the pack with a 0.94 score while keeping costs super low.
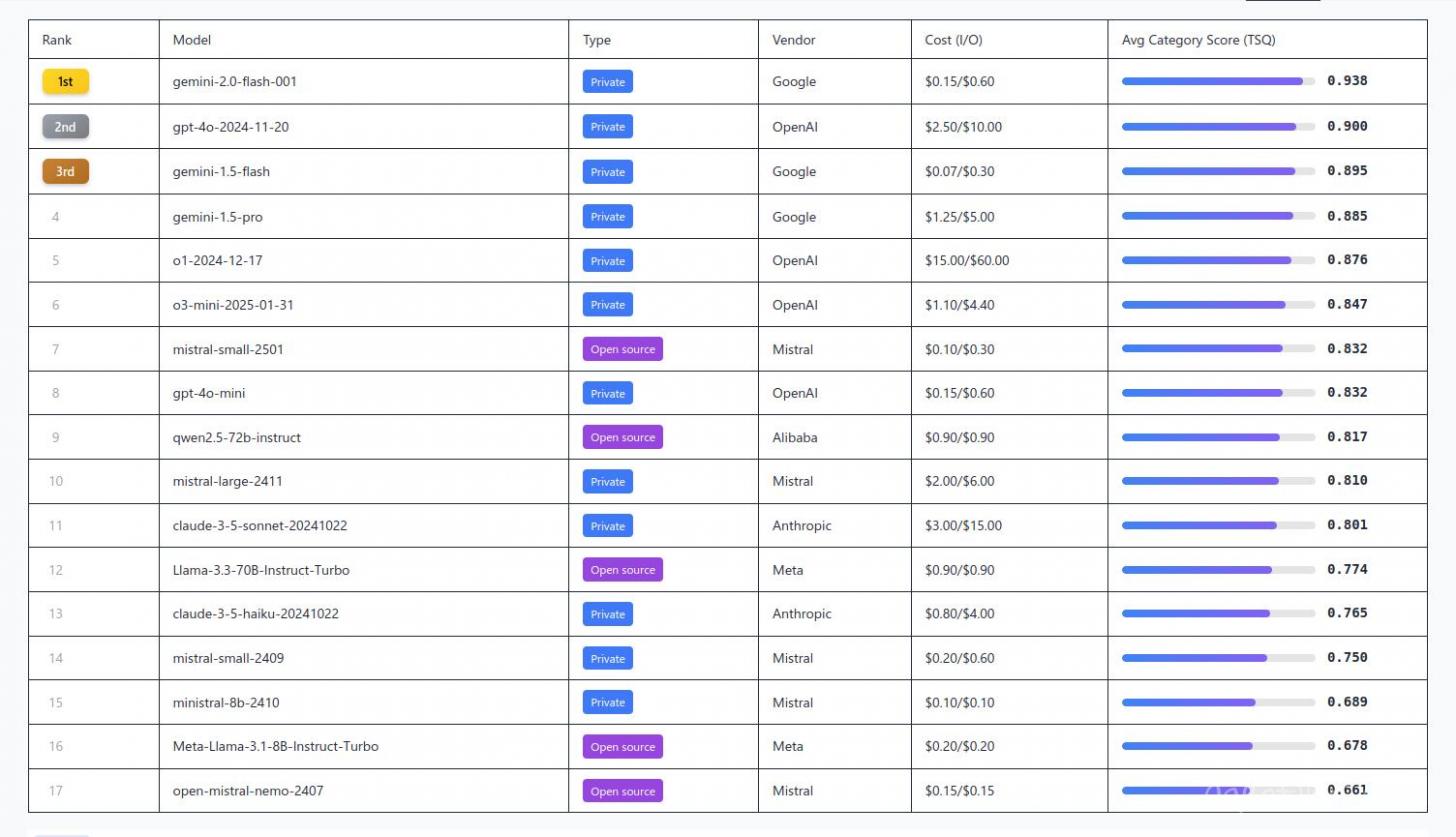
Cost vs. Performance.
The top three models only show a 4% performance gap, but their prices vary by 10x. A lot of users might be overpaying.
Open-Source Success.
Mistral AI’s mistral-small-2501 matches GPT-4o-mini with a 0.83 score, showing how smaller models can still punch above their weight.
Reasoning Skills.
Models like o1 and o3-mini handle function-calling well, but DeepSeek-R1 still lacks built-in support for it.
Handling Mistakes.
Claude-sonnet nails tool miss detection with a 0.92 score, but edge cases still trip up most models.
Trade-Offs in Design.
Some models handle long contexts well, while others are better at parallel tasks. o1 crushes long-context work (0.98) but struggles with parallel execution (0.43). GPT-4o flips that pattern.
Want to check out the full rankings? Head to the Agent Leaderboard.
Elvis, known online as @omarsar0, has a Ph.D. in NLP and founded DAIR.AI, an organization focused on scaling AI and building with large models. He worked at Meta AI on projects like Galactica LLM, Papers with Code, and PyTorch. He also created the widely used Prompt Engineering Guide, which has reached around 5 million users. Through DAIR.AI he teaches AI courses covering topics like AI agents, advanced prompt engineering, and Retrieval Augmented Generation, helping developers build smarter LLM applications.
Published: Feb 17, 2025 at 10:48 AM