Kokoro: A Breakthrough Open-Source TTS Model You Can Try Today
Here’s the deal—Kokoro is making waves in the world of text-to-speech (TTS). For those hunting a high-quality license-free option, this might be the one you’ve been waiting for.
Kokoro packs an impressive punch with just 82 million parameters, designed to turn text into natural-sounding audio. Released on December 25 2024, under the Apache 2.0 license, it’s open to everyone. Plus, there are already 10 unique voice packs available, and even an ONNX version for easy integration.
Why It Stands Out
In TTS competitions, Kokoro has outperformed much larger models despite using fewer parameters and less data. It topped the TTS Spaces Arena leaderboard with just 82M parameters and fewer than 100 hours of training data.
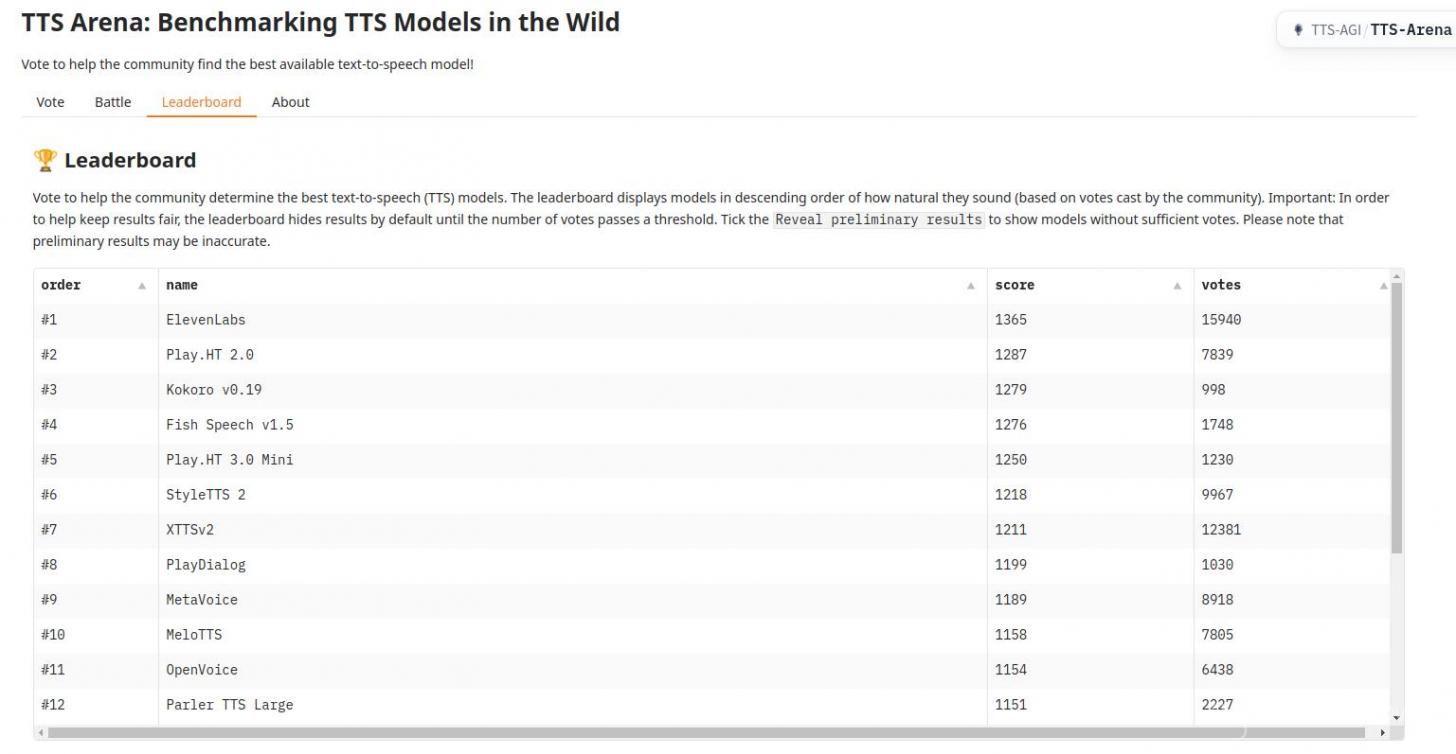
Here’s how it compares:
- Kokoro v0.19: 82M parameters, <100 hours, Apache license
- XTTS v2: 467M, >10k hours, proprietary license
- MetaVoice: 1.2B, 100k hours, Apache license
The results? Kokoro proves that smaller models can be just as effective—or even better—at creating natural-sounding voices.
Kokoro is built with:
- StyleTTS 2 for speech style transfer
- ISTFTNet for high-quality audio
- A decoder-only setup—keeping it lightweight
It supports both American and British English for now, with more to come.
Try It for Yourself
You can test Kokoro easily on platforms like Hugging Face or Replicate.
Model weights can be found at https://huggingface.co/hexgrad/Kokoro-82M/tree/main
Kokoro-onnx https://github.com/thewh1teagle/kokoro-onnx
It’s also quick to set up on Google Colab with a few simple commands, perfect for developers:
# 1ï¸âƒ£ Install dependencies silently
!git lfs install
!git clone https://huggingface.co/hexgrad/Kokoro-82M
%cd Kokoro-82M
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
!pip install -q phonemizer torch transformers scipy munch
# 2ï¸âƒ£ Build the model and load the default voicepack
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('kokoro-v0_19.pth', device)
VOICE_NAME = [
'af', # Default voice is a 50-50 mix of Bella & Sarah
'af_bella', 'af_sarah', 'am_adam', 'am_michael',
'bf_emma', 'bf_isabella', 'bm_george', 'bm_lewis',
'af_nicole', 'af_sky',
][0]
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
# 3ï¸âƒ£ Call generate, which returns 24khz audio and the phonemes used
from kokoro import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
# Language is determined by the first letter of the VOICE_NAME:
# 🇺🇸 'a' => American English => en-us
# 🇬🇧 'b' => British English => en-gb
# 4ï¸âƒ£ Display the 24khz audio and print the output phonemes
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
print(out_ps)
Kokoro's Limitations
Kokoro v0.19 has a few limitations tied to its training data and design:
- Voice Cloning: It doesn’t support voice cloning—likely due to its small training set of less than 100 hours.
- G2P Dependency: It uses espeak-ng for grapheme-to-phoneme conversion, which can cause errors in pronunciation.
- Training Data: The dataset is mainly long-form reading and narration, so it’s less suited for conversational speech.
- Model Size: At just 82M parameters, it can’t compete with much larger models like GPT-4o or Gemini 2.0 in terms of complexity or quality.
- Multilingual Support: While it’s possible by design, the training data is mostly in English, limiting its language variety.
What’s Next for Kokoro?
The creator has big plans. They’re working on a next-gen version with even more voices and languages, while keeping the same compact design and open license. Challenges like data quality and model stability are on their radar, but they’re optimistic about delivering even better results.
Want to be part of the journey? The project’s community-driven approach welcomes contributions, especially new datasets. Here's Kokoro Discord Server: https://discord.gg/QuGxSWBfQy

Community Feedback
Summary of Reddit Discussion on Kokoro's Limitations and Feedback
-
Lack of Fine-Tuning:
- Many users, like u/BattleRepulsiveO, wish Kokoro supported fine-tuning to allow custom voices beyond the provided voice packs. Some users remember mentions of future fine-tuning capabilities but can’t find updates confirming this.
-
Performance Observations:
- Kokoro performs well on long texts, avoiding pauses or errors common in other models like Fish or VoiceCraft.
- The ONNX implementation runs slower than PyTorch but is functional on limited hardware, like CPUs or lower-tier GPUs.
-
Hardware Compatibility:
- It works efficiently on GPUs like the 3090 with a small VRAM footprint. However, users like emimix report slower performance on Windows and suggest GPU/CUDA support could improve this.
- Speculations suggest the model could achieve decent speeds on smaller GPUs, like the 3060.
-
Setup and Usability:
- Some users, like VoidAlchemy, suggest that while the current setup works, the ONNX implementation could benefit from better installation instructions and a web UI.
- A few contributors, like u/WeatherZealousideal5, have already updated repositories with options for custom configurations and improved documentation.
-
User Preferences:
- Requests for features like Docker support, Mac GPU (MPS) compatibility, and integration with tools like SillyTavern or PipeCat are common.
Published: Jan 15, 2025 at 10:18 AM